How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
Kawin Ethayarajh - Stanford University
Accepted to EMNLP 2019
https://arxiv.org/abs/1909.00512
Abstract
본 논문은 “Contextualized Word Representation이 얼마나 문맥적인가?” 에 대한 분석 및 실험을 진행한다.
논문의 주요 포인트는 다음과 같다.
- Mesures of Contextuality
Contextuality 에 대한 정량적인 평가 기준을 제시한다. - Findings: Static vs. Contextualized
Word2Vec 또는 glove와 같은 Static한 표현과 Contextual 표현이 얼마나 다른가에 대해 논한다. - Results: BERT vs. ELMo vs. GPT-2
Contextual representation을 만드는 대표적 모델인 BERT, ELMo, GPT-2를 각각 비교한다.
결론
모든 단어의 문맥적 표현은 모델의 어떤 layer에서도 등방성(isotropic)이 아니다. 다른 문맥에서의 같은 단어가 다른 두 단어에 비해 cosine 유사도는 더 높지만, 이러한 self-similarity는 상위 layer에서 더 낮아지며 이는 contexualizing model이 상위 레이어에서 더욱 문맥에 특화된 표현을 만들어 냄을 의미한다.
1. Introduction
Static word embedding을 contextualized word representation으로 바꾸면 대부분의 NLP task에서 성능이 향상되었다.
이에 대해 대표적인 모델인 ELMo, BERT, GPT-2는 유명하지만 여전히 이들이 “어떻게 Contextual한 Representation 을 생성하는가? ” 에 대한 이해는 낮다.
“문맥적” 이라는 표현의 의미에 관한 고찰
1. 하나의 단어에 할당할 수 있는 표현이 무수히 많다?

- 하나의 단어에 할당할 수 있는 표현은 유한하고, 기본적으로 하나의 값이 할당되는 것인가?

논문은 해당 논제에 대해 ELMo, BERT, GPT-2의 각 레이어에서 representation의 기하학적 표현에 관한 연구를 진행함으로서 답을 찾았다.
2. Related Work
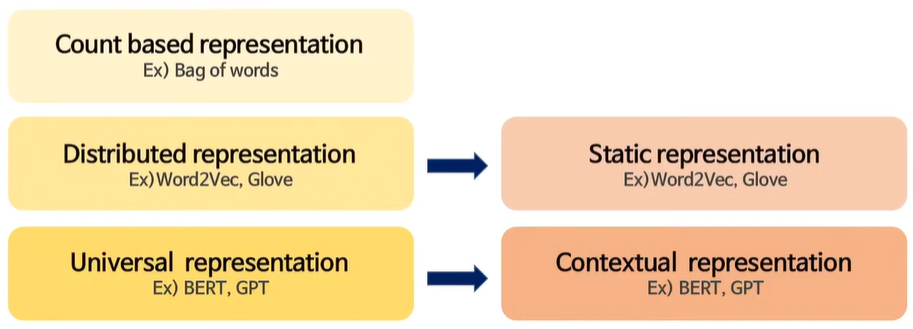
Text Representation을 위한 가장 기초적이고 직관적인 아이디어는 Bag of word와 같이 count 기반으로 representation을 만들어 내는 것이다. 두 번째는 Word2Vec이나 Glove와 같이 Distributed된 representation을 생성하는 것이고, 여기서 더 universal 한 표현을 만들어내는 BERT, GPT 등이 있다.
- Static representation
- 하나의 단어는 single vector로 존재한다.
- 단어를 나타내는 vector는 변하지 않고, 어떤 문장에서든 같다.
- Contexual representation (=Dynamic rep.)
- 문맥에 따라 하나의 단어는 여러개의 vector를 가질 수 있다.
- 다의어의 경우 static representation보다 유연하게 text 표현 가능하다.
- Downstream task에서 더 좋은 성능을 낸다고 알려져 있다.
3. Approach
3.1 Contextualizing Models

- ELMo
- Pretrained 2 hidden layers
- BERT
- Pretrained 12 hidden layers (base, cased ver.)
- GPT2
- Pretrained 12 hidden layers
BERT와 GPT2는 pair한 비교를 위해 각각 12개의 hidden layer로 셋팅하였다.
3.2 Data
STS dataset (SemEval Semantic Textual Similarity tasks from 2012-2016)
STS 데이터셋은 sentence pair가 존재할 때 두 문장의 similarity를 계산하는 방식이다.

두 문장에서 똑같이 dog 이라는 단어가 사용되었지만 문장이 다르기 때문에 dog의 의미가 같을수도, 다를 수도 있다. 만약 두 벡터가 같다면 contextualization이 되지 않았다고 추론하고, 두 벡터가 다르다면 조금 contexualization이 되었다고 해석할 수 있다.
또한 논문에서는 5개 미만의 unique한 context의 단어는 고려하지 않았다고 한다.
3.3 Measure of Contextuality
연구는 Contextuality를 평가할 수 있는 세 가지 지표를 제공한다.
1. Self similarity (SelfSim)
: 주어진 모델의 각 레이어에서, 동일한 단어가 모든 context에서 가지는 contextualized representation의 평균 cosine similarity

- $w$ : word in sentence
- {${{s1,s2,...,sn}}$} : set of sentences
- {$i_1,i_2,...,i_n$} : set of indices
→ $w = s_1[i_1]=...=s_n[i_n]$
- $f_l(s,i)$ : layer l 에서 s[i] 에 mapping되는 function

e.g. high self-sim for ‘dog’ across context
예를 들어 dog이라는 단어의 self-similarity가 굉장히 높다면, 전체 context에 걸쳐 이들이 비슷한 공간에 분포하고 있다고 추론한다.
만약 layer l이 문맥화 되지 않았다면 word는 모든 context에서 동일한 의미를 가지고 SelfSim 은 1이 될 것이다.
즉, 특정 단어의 SelfSim이 낮을수록 더욱 문맥화된 표현이라고 볼 수 있다. BERT의 경우 layer를 거칠수록 SelfSim이 낮아짐을 확인하였다.

Example : BERT
2. Intra similarity (IntraSim)
: 동일한 문장 (같은 문맥) 에서 등장하는 모든 단어들 사이의 평균적인 cosine similarity


e.g. low intra-sim for ‘The dog is wet’
예를 들어 낮은 intra similarity를 가지는 문장이 있고, 문장을 구성하는 단어들이 The, dog, is, wet 이라면 각각의 단어가 상이한 공간으로 맵핑되고 있기 때문에 intra similarity가 낮은 상황이라고 말할 수 있다.

Example : BERT, GPT
Intra Sim은 벡터 공간에서 context-specific하게 벡터가 조정되는지 측정하는 지표이다. 위에서 BERT와 GPT2는 layer를 거칠수록 IntraSim이 높아지는 것을 확인할 수 있다. BERT의 경우 마지막 레이어에서는 수치가 감소하지만, 변화의 폭을 보면 GPT2보다 더 크다. 둘 다 레이어를 거칠수록 동일한 문장의 단어들이 비슷한 공간으로 매핑되고 있다고 볼 수 있다.
SelfSim & IntraSim
1. $IntraSim_l(s), SelfSim_l(w)$ 이 동시에 낮은값일 때
⇒ context에 specific한 representation 제공
2. $IntraSim_l(s)$은 높고 $SelfSim_l(w)$ 은 낮으면
⇒ 문맥이 별로 미묘한 차이가 없으며, 벡터 공간에 밀집된다
3. Maximum explainable variance (MEV)
: 다양한 문맥에서 Word representation의 가장 첫번째 principal component로 설명되는 분산
즉, 첫 번째 요소가 가지는 분산에 대해 특징값을 찾아내는 과정이다.

- $f_l(s,i)$를 layer l 에서 s[i] 에 mapping되는 function
- $[f_l(s_1, i_1), ... , f_l(s_n, i_n)]$ : occurrence matrix
- $σ_1,...,σ_m$ : First singular values of matrix
MEV 는 단어 w의 문맥화된 표현의 분산의 비율이다. 이는 static embedding이 단어의 문맥화된 표현을 얼마나 잘 대체할 수 있는지를 보여주는 지표가 될 수 있다.
MEV가 1에 가깝다면 static embedding과 유사하고, 0에 가깝다면 contextualized representation으로 표현되었다고 본다.
Result in Measures
1. Lower self-similarity
2. Higher intra-sentence similarity
3. Lower maximum explainable variance
지표의 결과가 위의 세 case로 나타난다면, 이는 more context-specific 한 Representation임을 의미한다.
4. Findings
4.1 (An)Isotropy


✓ Contextualized representations는 input이 아닌 layer에서 anisotropic임
✓ Contextualized representations는 higher layer로 갈수록 anisotropic임
이는 동일한 w에 대한 벡터가 전체 vector space에 퍼지도록 분포되는 것이 아니라 이등방성을 가지는 모양으로 vector space에 맵핑되고 있었음을 의미한다.
논문에서는 이 Isotropy에 대해 확인해 볼 수 있는 실험을 진행했는데, radom 하게 word를 sampling 한 다음 각각 word에 대해 cosine-similarity의 평균을 확인해보았다.

ELMo의 경우 2개의 layer만 있기 때문에 전반적으로 깊은 양상을 확인할 수는 없지만 다른 두 모델에 비해서는 낮은 값을 가지고 있는 것을 확인할 수 있다.
GPT와 BERT는 모두 output layer에 가까워질 수록 cosine-similarity가 높아지는 양상을 보였으며 BERT는 마지막 레이어에서 감소하였다.
4.2 Context-Specificity
그 다음은 context-specificity를 확인하기 위해 위의 세 정량 지표에 대한 실험을 진행하였다.
- Self-Similarity

Self-Similarity의 관점에서도 상위 layer에 가까워질수록 더욱 Contextualized representations이 생성되었음을 확인할 수 있다. 특히 문장에 자주 등장하는 stopword의 경우 굉장히 낮은 self-similarity를 보였다.
즉, 단어들은 여러가지 Contextualized representations중에 하나에 할당되는게 아니며 지속적으로 유한한 공간에서 변화한다는 것을 나타낸다.
- Intra sentence Similarity

해당 실험의 결과는 Contextualized representation을 생성한다고 알려진 세 가지 모델의 representation은 명백히 다름을 보여주고 있다.
Transformer 구조를 따르는 BERT와 GPT도 굉장히 다른 모습의 intra sentence similarity를 보이고 있다.
ELMo
✓ 같은 문장의 단어들이 굉장히 큰 유사도를 가진다.
BERT
✓ ELMo에 비해서 낮은 유사도를 가지지만, 이 결과는 ELMo보다 generalized된 context representation을 만들어낸다고 볼 수 있다.
GPT-2
✓ 가장 낮은 Intra-sentence similarity를 가진다.
✓ 동일한 문맥이라도 각 단어의 의미가 보존된다.
✓ 이는 언어자체를 잘 이해하는 contextualized representation이라고 볼 수 있다.
✓ 단지 높은 IntraSim을 가진다는 것이 contextual representation이라고 주장할 수 없는 근거가 된다.
4.3 Static vs. Contextualized
- MEV

논문에서는 Contextualized representation들의 분산이 5%보다 작을경우 static으로 간주하고 있다. 이 때 5%는 threshold이며 실험적으로 설정한 best case scenario값이라고 한다.
MEV가 낮을수록 단어들은 무한한 공간에 할당되고 context에 민감하다고 볼 수 있다.
6. Conclusion
- Contextualized representation 이 실제로 문맥을 어떻게 표현하는지 알기 위해 세 가지 지표를 사용하였다.
- 실제로 각 모델에 따라 생성되는 Contextualized representation은 달랐으며 동일한 모델의 레이어마다 생성해내는 representation도 달랐다.
- Contextualized representation이 NLP task에 대해 좋은 성능을 보이는 이유를 입증해냈다. 언어는 문맥에 따라다양한 의미를 가질 수 있고, 이를 포착해 냈기 때문이다.
Ref.
https://ws-choi.github.io/blog-kor/nlp/deeplearning/paperreview/Contextualized-Word-Embedding/
https://www.youtube.com/watch?v=d05ype2cVQc
'AI' 카테고리의 다른 글
| [NLP] hdbscan으로 키워드 클러스터링하기 (0) | 2023.03.13 |
|---|---|
| [NLP] 텍스트 내의 명사구를 추출하는 방법 (0) | 2023.02.26 |
| [NLP] OpenAI GPT-3 에서 토큰을 선택하는 방식 (feat. 샘플링) (0) | 2022.11.13 |
| [NLP] 텍스트 마이닝의 개념과 전체적인 프로세스에 대하여 (0) | 2021.12.06 |
| [NLP/논문 리뷰] 위키피디아 기반 개체명 사전 반자동 구축 방법 (0) | 2021.09.23 |



