Abstract
목적:
본 연구에서는 개체명 사전을 반자동으로 구축하는 방법을 제안한다.
방법:
1. 능동 학습을 이용하여 위키피디아 분류정보로 구성된 가상 문서를 개체명 범주 당 하나씩 생성한다.
2. 잘 알려진 정보검색 모델인 BM25를 이용하여 위키피디아 엔트리와 가상문서 사이의 유사도를 계산한다.
3. 유사도를 바탕으로 각 위키피디아 엔트리를 개체명 범주로 분류한다.
1. 서론
기존의 개체명 인식 방법은 크게 규칙 기반과 확률 기반 두 가지로 나뉜다.
1. 규칙기반 방법
2. 확률기반 방법
규칙 기반 방법
- 정규표현식과 같은 패턴과 개체명 사전을 이용하는 방법
- 좋은 패턴의 생성 방법과 개체명 사전의 크기가 성능 향상을 위한 요건이 된다.
확률 기반 방법
- 대용량의 개체명이 태깅된 말뭉치(corpus) 로부터 확률을 학습하고, 그것을 이용하여 개체명 범주를 결정하는 방법
- 성능 향상을 위해 최적화된 자질(feature)을 찾는 것이 중요하다.
- 일반적으로 어휘수준의 자질(형태소와 그 품사), 문법수준의 자질(의존구조 등), 항목색인(list-lookup) 자질 (개체명 사전 n-어절 색인) 등이 많이 사용된다.
즉 개체명 인식 방법의 두 가지 큰 방법론에서 개체명 사전은 성능향상에 중요한 역할이다.
문제점
- 개체명의 기준이 되는 개체명 범주(named entity category)는 표준화가 되어있지 않고, 필요에 따라 달라진다.
- 개체명의 사전적 의미인 “한정된 속성으로 단독의 사물을 나타내는 개념”에 부합되지 않는 것을 개체명으로 보는 경우도 있다.
- 예를 들어 “알버트 아인슈타인”은 명확하게 “Person”의 개체명으로 볼 수 있지만, “김밥”, “라면”은 엄밀히 따지면 개체명이 아니다.
- 그러나 질의응답 시스템의 지식구축이나 사용자 질의 분석에는 중요한 역할을 할 수 있으므로, 많은 연구에서 개체명으로 취급하기도 한다.
사용 용도에 따라 다양하게 정의될 수 있는 개체명 범주를 위해 반자동 개체명 사전 구축한다.
3. 정보검색 기반 개체명 사전 구축
위키피디아 페이지에서 분류정보는 해당 엔트리의 특성을 잘 설명하는 단어들로 구성되어있다.

위의 단어들을 보면 "포드 모터 컴퍼니"는 "Organization"에 해당함을 알 수 있다.
구축 방법
1. 초기 가상문서 구축
2. 가상문서 확장
3. 개체명 사전 구축
3.1 초기 가상문서 구축
1. 최소한의 엔트리를 갖는 개체명 사전을 구축하는 단계
DBpedia ontology의 685개 계층 구조에서 임의로 K개를 선택하여 개체명 범주로 사용하였다. 그리고 각각의 범주별로 임의로 20개 위키피디아 엔트리를 선택하여 가상문서를 구축하였다.
2. 개체명 범주를 표현하는 가상문서를 구축
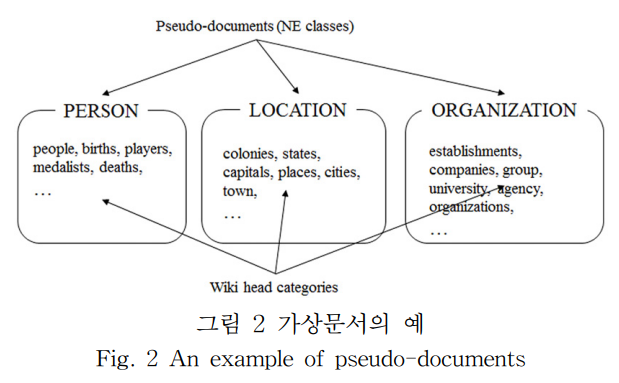
예를 들어 'Organization'범주의 초기 개체명 사전에 '포드 모터 컴퍼니'가 있다면, 그 분류정보인 '미국의 자동차 제조 기업', '미국의 엔진 제조업체', '미국의 다국적 기업', '미국의 브랜드', '미간주의 기업' 등 으로 구성된다.
본 논문에서는 마지막 어절을 뽑는 간단한 휴리스틱으로 분류정보를 정규화해서 핵심분류정보(Wiki head-category)를 추출하였다.위의 예시의 경우 '제조업체', '기업', '브랜드'가 추출되고 이 어휘들이 Organization을 표현하게 된다.
3.2 가상문서 확장
초기 가상문서는 최소한의 위키피디아 엔트리를 이용하여 구축되었기 때문에 각 문서를 표현하는 어휘들의 종류가 적을 수밖에 없고, 이를 해결하기 위해 어휘 표현을 확장해야 한다.
능동 학습 방법(active learning) 이용
기존 가상문서에 없는 핵심 분류정보가 많이 포함된 엔트리를 발견하면, 수작업으로 기존의 가상문서에 추가해 지속적인 업데이트를 진행해 확장해 나간다.
예를 들어 선택된 엔트리가 "포드 모터 컴퍼니"이고, 핵심 분류 정보가 '제조업체', '기업', '브랜드' 인 경우, 수작업 태깅으로 “Organization”으로 분류했다면, "Organization" 가상문서의 본문에 '제조업체', '기업', '브랜드'가 추가된다.
이 과정을 n회 반복하여 확장한다.
3.3 개체명 사전 구축
이전 단계에서 확장된 가상문서를 이용해 개체명 사전을 구축해 나간다. 여기서 분류대상이 되는 엔트리의 분류정보를 질의로 하고 해당 질의와 가장 유사한 가상문서를 찾아 개체명을 분류하는 시퀀스로 사전을 반자동으로 구축해 나간다.
분류대상 엔트리에 개체명 범주를 할당하기 위해 정보검색에서 많이 사용되는 BM25모델을 사용한다.
4. 실험 및 분석
4. 1 실험 데이터
DBpedia에서 제공하는 온톨로지와 엔트리, 분류정보 쌍을 저장한 데이터를 가공하여 사용하였다.
제공된 온톨로지는 685개 계층구조로 구성된 개체명 범주가 태깅되어 있다. (한국어의 경우는 그 중 331개의 범주의 엔트리만 존재)

논문에서는 범주의 크기에 대한 실험을 위해 3개, 14개, 27개를 임의로 선택하여 데이터를 구축하였다.
4.2 실험 결과
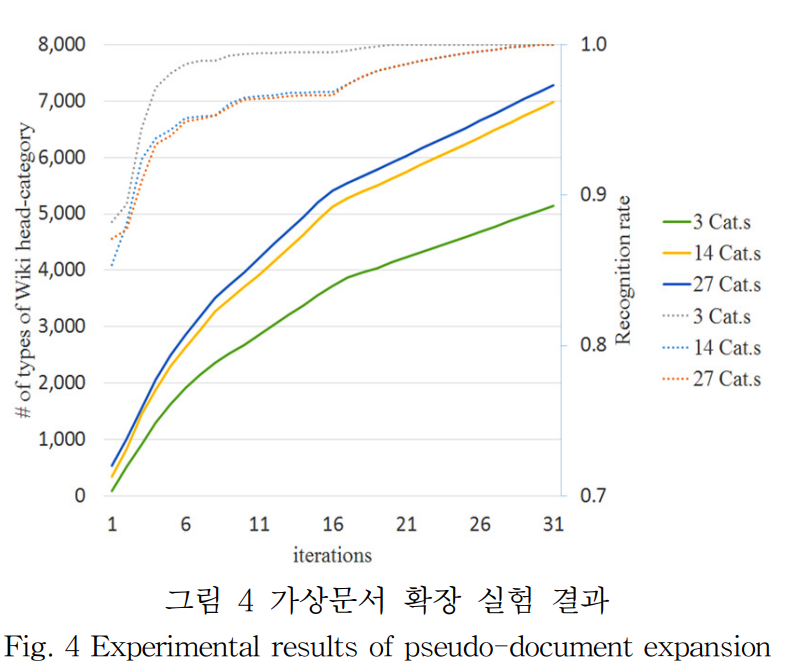
점선은 엔트리의 인식률, 실선은 가상문서에 포함된 핵심 분류정보 종류의 수를 나타낸다.
핵심 분류정보의 종류는 매회 반복마다 꾸준히 증가하지만, 엔트리의 인식률은 능동학습 방법으로 약 5회 반복했을 때까지 가파르게 상승 후 완만해진다.
이것은 반복 초반에 수집된 핵심 분류정보들이 여러 엔트리에 적어도 하나 존재함을 의미한다.
4.2.4 오류 분석
분류의 수가 적은 3개 범주의 경우를 제외하고 14개, 27개 범주를 봤을 때, 평균 이하의 성능을 보이는 범주들은 크게 두 가지 유형으로 보인다.
1. 전체 엔트리가 너무 적어(100개 안팎) 확률적으로 선택될 가능성 자체가 적은 오류
가상 문서 확장에서 선택될 확률이 적은 것이 원인으로 추정된다. 예를 들어 14개, 27개 범주의 "Plant", "Animal"은 두 범주의 엔트리를 합하더라도 겨우 5%일 정도로 양이 적다. 따라서 각각은 높은 정확률을 보이지만 전체 성능은 낮아졌다.
2. 개체명 범주간의 성격이 유사해서 잘못 태깅되는 오류
27개 범주의 “Company”와 “Organization”은 앞의 경우와 반대로 인식률은 평균 98.60%로 높지만 정확률은 평균 49%로 떨어지는 양상을 보였다.
5. 결론
개체명 범주가 3개, 14개, 27개일 경우에 대하여 가상문서 확장을 30회까지 반복하며 실험하였다.
그 결과 10회의 가상문서 확장을 수행했을 때 평균 0.9028 (Macroaverage F1-score), 0.9554 (Micro-average F1-score)의 성능을 보였고, 더 많은 확장을 수행했을 때에 비해 성능 향상 폭이 가장 높았다.
'AI' 카테고리의 다른 글
| [NLP] hdbscan으로 키워드 클러스터링하기 (0) | 2023.03.13 |
|---|---|
| [NLP] 텍스트 내의 명사구를 추출하는 방법 (0) | 2023.02.26 |
| [NLP] OpenAI GPT-3 에서 토큰을 선택하는 방식 (feat. 샘플링) (0) | 2022.11.13 |
| [NLP/논문리뷰] How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings (0) | 2021.12.27 |
| [NLP] 텍스트 마이닝의 개념과 전체적인 프로세스에 대하여 (0) | 2021.12.06 |



