해당 글은 텍스트 분석 강의를 바탕으로 작성하였습니다.
첫 번째 강의인 Text Analytics는 텍스트 분석의 전체적인 개요와 프로세스에 대한 설명으로 이루어져있으며, 목차는 다음과 같다.

01 Text Analytics: Overview
강의 링크: https://www.youtube.com/watch?v=UInnl60pzkA&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm
Background
80% 이상의 새로 생기는 데이터들은 비정형 데이터이고, 그중에서도 text data가 큰 비중을 차지한다.
검색어에 맞는 문서를 반환(retrieval) 해주는 것 만으로는 충분하지 않다.
즉, 새로운 지식을 찾아내는 것이 요구된다는 것이다.
Definition
Text Data를 다양한 방법론으로 분석하여 의미있는 지식을 추출하는 것이다.

Applications
1. 한국은행을 포함한 전 세계 중앙 은행 총재들의 주기적인 연설문 또는 공고문을 영어로 번역한 웹사이트

연설문 속 단어를 통해 각국의 통화정책에 대한 방향성, 즉 비슷한 국가들에 대해 파악해 보자는 목적
문서를 특정 길이의 벡터로 표현하여 유사성을 계산하고 고차원의 피처를 차원 축소하여 나타냄
2. 추천 (Recommendation)

위에서 가볼만한 곳으로 뜨는 여행지들은 사용자의 블로그에 대한 텍스트 본문을 분석하여 가장 긍정적인 뉘앙스가 많았던 여행지 순으로 보여주는 것이다.

다음은 맛집 랭킹을 보여주는 다이닝 코드 앱이며, 광고성 블로그는 필터링하고 인플루언서들의 영향력을 크게 반영한 서비스라고 한다.
3. 질의응답 (Question Answering)
구글에서는 위키 데이터를 통해 질문이 주어지면 답이 어디에 있는지 찾아가는 방식으로 QA 데이터를 생성한다.
📃 Papers with Code - The latest in Machine Learning
특정 task에 대해 sota에 가까운 성능을 나타내는 논문들, 혹은 해당하는 github 코드를 공유하는 site
4. 챗봇 (Dialogue system)
QA의 궁극적 목적은 대화형 시스템을 만드는 것이며, 지금까지는 사용자가 제시하는 키워드에 대해 rule base로 적합한 답변을 만들어 주었지만, 최종 목적은 사람과 구별이 불가할 정도의 챗봇을 만드는 것이다.
Challenges
하지만 텍스트 마이닝에는 해결이 힘든 도전과제도 존재한다.
- 차원의 수가 굉장히 크다 (word, phrases, etc.)
- 한국어는 위키기준 110만개의 단어, 영어는 17만개의 단어가 존재
- 단어의 개념 자체가 모호하다
- 장명준은 즐겁게 오버워치를 하다가 지도교수에게 들켰다.
- 강필성 교수는 우연히 들른 신공학과 220호에서 게임을 하는 한 학생을 목격했다.
사람의 경우는 문장 a, b가 같은 의미라는 것을 본능적으로 파악할 수 있지만 컴퓨터는 단어 빈도 기반이기 때문에 두 문장을 전혀 관계없는 문서로 파악할 확률이 높다.
Text Structures
얼마나 "비구조화" 되어있느냐? 를 의미하며 크게 두개로 나뉠 수 있다.
- Weakly structured
- 어느 정도의 포맷이 존재
- research papers, legal memoranda, news stories, etc.
- Semi-structured
- weakly structured 보다는 좀더 포맷이 확장
- E-mail, HTML/XML web pages, pdf files, etc.
02 TM Process 1: Collection & Preprocessing
강의 링크: https://www.youtube.com/watch?v=Y0zrFVZqnl4&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=2
Target Data
📌 연구 관점에서 봤을 때...
텍스트 데이터에 대한 알고리즘을 개발했을 때 벤치마크 알고리즘과의 성능을 비교하고, 제안한 알고리즘이 어떤 측면에서 성능이 우수한지 입증하기 위해서는 다양한 open dataset이 필요하다.

Text Preprocessing Level 0: Text
텍스트를 처리하는 단계에서 가장 첫 번째는 불필요한 정보(html 문법, 하이퍼링크 등) 제거 후 본문만 저장하는 것이다.
하지만 메타 데이터가 중요할 경우도 있는데, 뉴스 기사의 경우 기자, 날짜, 카테고리, 언어 등이 속한다. 이러한 메타 정보는 향후 문서 분류나 시간의 흐름을 분석할 때 중요한 단서가 된다.
만약 이미지를 통해서 텍스트를 생성하거나 요약하는 모델의 경우 아티클 속 이미지의 캡션이 중요한 피처로 쓰일 수 있다.
Text Preprocessing Level 1: Sentence
텍스트 분석 시 사용하는 하위 단위는 문장이다. 문장 자체를 정확하게 판별하고 구분하는 것이 필요하다.
- 형태소 분석에서는 문장 안에서 tag들의 확률을 최대화 하는 것
- 추출요약의 경우 문장이 제대로 분리되어있다는 가정 하에서 어떤 문장이 중요한 문장인지 선정
Problem
문장 분리의 기준으로 ., ! ,? 같은 종결 문자를 사용할 수 있지만 해당 문자가 종결을 의미하지 않는 Hard case의 경우 문제가 된다.

Solution: Rule-based Model
해당 문제에 대한 대안으로 하이브리드 방식이 가장 문장 분리 정답률이 높았다. 하이브리드 방식은 아래의 두 step으로 이루어진다.
- KOALA nlp에서 만든 문장 분리기로 1차 분리
- rule-base로 2차 분리
하지만 KOALA의 경우 문장부호에 의존성이 강해서 문장부호 제거시 성능이 23.06으로 현저히 떨어지게 된다.

사람의 경우 문장 분리가 어렵지 않지만, 컴퓨터의 관점에서는 꽤나 어려운 task일 수 있다.
Text Preprocessing Level 2: Token
토큰이란 가장 작은 단위의 의미 단위이다.
영어에서 알파벳 a,b,c..한글에서 초성,중성,종성은 의미가 없기 때문에 토큰이 아니다. 단어, 숫자, 공백 의 경우 의미를 갖기 때문에 토큰의 범주에 속한다. 토큰화의 경우도 문장 분리와 마찬가지로 쉬운 task는 아니다.
John's sick 은 하나의 토큰인가? 두 개의 토큰인가?
- 하나 → 파싱관점에서 문제 (동사가 어디있는가)
- 둘 → 그렇다면 John's house는 두 개의 토큰인가?
hyphen(하이픈)이 있는 경우는 하나의 토큰인가?
- database vs. data-base vs. data base
신조어나 특정 분야에서 전문적으로 쓰이는 약어들의 경우는?
- C++, A/C, :-), ... , ㅋㅋㅋㅋㅋㅋㅋㅋ
몇몇 언어는 띄어쓰기를 사용하지 않는다 (ex 중국어)
- 어디서 단어를 구분하느냐에 따라 문서의 내용이 완전히 달라진다.
일관성 있는 토큰화는 이후 step에서 매우 중요하다.
단어 빈도에서 멱함수 법칙 (Power distribution)

다음은 옥스포드 영영사전에서 가장 빈도가 높은 단어 100개이며, 상위 단어를 보면 the, be, to, of, and 등 관사, be동사, 전치사, 접속사 등이 차지하고 있다.

위의 그래프는 위키피디아에서 단어 빈도 분포이며, 위에서 x축은 옥스포드 표에서의 순위, y축은 위키피디아에서 해당 단어가 등장한 빈도에 속한다.
또한 둘 다 log/log scale 이며 그 결과 순위가 높아짐에 따라 직선 형태로 빈도가 줄어드는 것을 볼 수 있다.
이를 만약 linear scale로 표현하게 된다면 아래와 같은 형태로 급격하게 줄어드는 양상을 보일 것이다.

텍스트 마이닝에서는 빈번하게 사용되는 단어가 더 중요한 것이 아님을 의미한다.
즉 빈번하게 사용되는 단어일수록 관사나 접속사와 같이 문법적인 기능을 하되 의미(sementic)관점에서는 중요하지 않을 가능성이 매우 높다.
불용어 (Stop-words)
분석 관점에서 어떠한 정보도 포함하지 않는 단어
분명 특정 언어에서 쓰이면서 문법적 기능을 하거나, 문장의 의미를 미묘하게 변화시키지만 해당 단어(혹은 토큰)을 제외시켜도 전체적인 의미를 잃어버리지 않는다.
English: a, about, above, across, after, again, etc.
한국어: ~습니다, ~로서(써), ~를 등
어간추출 (Stemming)
텍스트 분석에서는 차원을 줄이는 것이 중요하게 여겨졌다. 이 관점에서 보면 한글이나 영어의 똑같은 원형의 단어로부터 파생되는 어휘가 다를경우, 즉 품사가 달라지거나 과거형/현재형/미래형으로 변형되었을 경우 이를 하나의 basic form으로 맞춰주는 작업이 중요한데 대표적으로 Stemming과 Lemmatization이 있다.
Stemming은 서로 다른 형태를 가지고 있는 단어들이 하나의 stem 즉 정규화된 form 으로 바꿔주는 것이며, 이때 stem은 각각의 단어들이 공통적으로 가지고 있는 가장 긴 음절을 뜻한다.
표제어 추출 (Lemmatization)
stemming이 base form을 찾는 것이라면, Lemmatization은 해당 단어들이 가지고 있는 품사를 보존하면서 단어의 원형을 찾는 것이 목적이다.

stemming은 사전에 존재하지 않는 단어일 수도 있다는 단점이 존재하는 반면 훨씬 더 원형을 기본으로 줄여나가기 때문에 최종적으로 남는 결과물의 개수가 적다.
차원 축소 관점에서는 stemming이 효과적, 품사 보존 관점에서는 lemmatization이 효과적이다.
03 TM Process 2: Transformation
문서를 어떻게 연속형의 숫자 벡터로 표현할 것인가?
Why?
아직까지는 굉장히 많은 머신러닝 혹은 인공지능 알고리즘들이 숫자화된 정보를 처리하는 데 훨씬 특화되어있기 때문이다.
Bag of Words
하나의 문서는 그 문서에 사용된 단어의 빈도 혹은 출현 여부로 표현된다.
TF-IDF
특정한 단어가 어떤 문서에 얼마만큼 중요한지에 대해 가중치를 부여한다.

- tf (Term Frequency): 문서에서 단어가 출현한 빈도 수
- df (Document Frequency): 단어가 corpus 내에서 출현한 빈도 수
관사 The가 거의 모든 문서에서 1번씩 출현했을 때, inverse df는 N/N=1이 되고,그 결과 log1=0이 되어 수식이 0이된다.
단어 w가 문서 D에서 중요하다면 D에서 빈도는 높게, 전체 corpus에서 빈도는 낮아야한다.
One-hot-vector 표현
BOW는 원핫 벡터를 기본으로 삼는데, 이는 특정한 하나의 단어를 표현하기 위해 전체 길이가 vocabulary의 size이고 해당 단어의 위치에는 1, 나머지는 0의 값을 갖는 vector이다.
Problem
문제는, 두 단어의 유사성을 계산할 수 없다는 것이다. 어떠한 임의의 두 벡터를 내적해도 0이 나오게 되기 때문이다.
Solution: Word to vectors
그에 대한 대안으로써 Word to Vector가 등장하게 되었는데, 이는 단어를 N 차원의 실수 공간에 표현하는 것에서 시작되었다.
Word Vectors
벡터의 차원의 수는 vocabulary size보다 작아야하며, 각각의 변수들은 전부 0 또는 1이아닌 실수값을 갖도록 한다.
충분한 corpus로 학습을 하게 되면, 단어 사이의 유사성이 보존되는 vector를 만들어 낼 수 있게 된다.

최근에는 Wor2vec, GloVe, FastText와 같이 사전 학습된 Word Model을 이용할 수 있으며, 한발 더 나아가 Elmo, GPT계열, BERT계열의 사전학습된 언어 모델을 사용할 수 있다.
End User들은 충분히 많은 corpus로 학습되어있는 plm의 vector를 가지고 downstream task에 적용시킬 수 있는 환경이 조성되어있다.
04 TM Process 3: Dimensionality Reduction
차원 축소는 크게 두 가지로 나뉜다.
- Feature selection
- Feature extraction
Feature subset selection
특정한 목적에 걸맞는 가장 최적의 변수 집합을 선택한다. 이때, 주어진 변수를 가공하거나 변형시키지 않는다.
Ex) 문서를 감성분석 하는 supervised learning task에서...
긍정적 문서에만 자주 사용되거나 부정적 문서에서만 자주 사용되는 특정 단어들이 존재할 것이다.

예를 들어 영화 리뷰 데이터에서 "핵노잼" 이라는 단어는 긍정적 문서보다 부정적 문서에서 많이 등장할 것이며, information gain 값이 클 것이다.
이처럼 주어진 수식들을 이용해서 어떤 토큰(or단어)들이 원하는 task에 유의미한지 혹은 유의미하지 않은지 판별하는 것이 feature selection의 개념이다.
Feature subset extraction
주어진 데이터의 차원이 $d$ 일때 extraction 후의차원 $d'$ 은 반드시 원래 차원보다 작아야 한다.
핵심은, 원래 데이터가 가진 정보는 최대한 보존하면서 훨씬 더 적은 수의 dataset을 구축하는 것이다.
대표적인 방법론은 LSA(Latent Semantic Analysis)이다.
LSA(Latent Semantic Analysis)
하나의 matrix를 세 개의 matrix로 분해(decomposition)을 한 후 두 개의 matrix만을 사용하여 차원을 축소한다.

텍스트 마이닝에서 SVD란...

m개의 Term으로 이루어진 n개의 Document를 가지는 corpus에서, 이 corpus는 세 개의 matrix로 분해될 수 있으며 이때 $Σ$ 의 대각 행렬의 원소는 각각의 U와 V에 해당하는 컬럼들의 값들이 얼마나 중요한가를 나타낸다.
이때, 전체의 모든 R차원을 사용하지 않고 R보다 적은 k개의 차원만을 사용해서도 데이터를 재구축 할 수 있다.
n차원의 document를 k차원으로 바꿀수도, m차원의 term을 k차원으로 바꿀 수도 있기 때문에 문서를 축약하는데 사용되기도하고 단어를 축약하는데 사용되기도 하는 방법론이다.
Topic Modeling (LDA)
Unsupervised Learning 관점에서, 문서 집합을 관통하고있는 주요 주제를 판별한다. 주요 주제는 두 가지로 나타난다.
- 해당하는 주제들은 각각의 문서들에 대해 얼마만큼의 비중을 가지는가
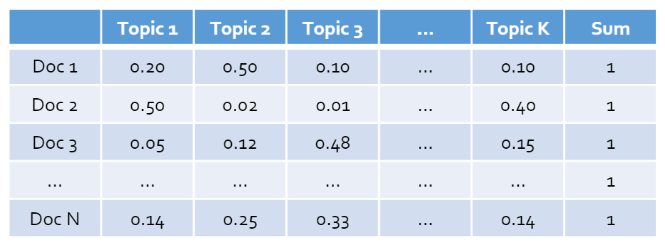
2. 각각의 주제별로 주요 핵심 키워드는 무엇인가

document는 k개의 topic을 차원수로 가지는 연속형의 벡터로써 표현할 수 있다. 위의 두 표를 보면 document별로 topic들의 확률의 합은 1이되고, topic별로 word들의 확률의 합은 1이된다.
Doc2Vec (Document to Vector)
최근에는 feature extraction관점에서 word2vec을 확장시킨 doc2vec이 등장하였는데, 각각의 document를 분산된 표현으로 만들어내는 것이 가능하게 되었다.

word2vec에서는 특정 단어들에 대한 임베딩 값을 찾았다면, doc2vec에서는 paragraph id 라는 개념을 이용한다.

paragraph id는 문서의 id가 단어와 똑같은 차원으로 표현이 되고, 해당 벡터를 학습시키면 문서와 단어가 동일한 차원의 공간 상에 표현이 될 수 있는 기법이다.
05 TM Process 4: Learning & Evaluation
마지막 단계는 원하는 downstream task를 학습하고 평가하는 단계이다.
Learning Task 1: Classification
(x,y)의 Label이 있는 document 들이 주어졌을 때, y=f(x)에 해당하는 알고리즘을 학습시킨 뒤 새로운 unlabeled document에 대해 category(y)를 예측하는 것이다.
📝 Task 종류
- Spam filtering
- Sentiment Analysis
Learning Task 2: Clustering
문서집합에 있는 주요한 topic과 topic간의 관계식을 찾아내고 문서를 다 읽지 않더라도 현재 어떤 일이 일어나고 있는지 파악하게 해 준다.
Learning Task 3: Information Extraction/Retrieval
세 번째 태스크는 정보를 추출하고 검색하는 것이며, 대표적으로는 QA가 있다. Text로 이루어진 dataset에 한해서 질문이 주어졌을 때 답을 내놓는 것이다.
가장 유명한 벤치마크 데이터셋으로는 SQuAD dataset 1.0, 2.0 등이 있으며, 해당 데이터셋을 이용하여 여러가지 알고리즘을 테스트하고 벤치마크 해볼 수 있다.
한국어 데이터로는 KorQuAD 데이터셋이 공개가 되어있기 때문에 한글 자연어 처리시 알고리즘 검증에 있어 해당 데이터셋을 이용하면 되겠다.
Topic Modeling은 이전에는 feature extraction 관점에서 등장하였지만, 전반적인 corpus에서 어떠한 주제들이 대다수를 차지하고 있고 그 주제들이 시간의 흐름에 따라 어떻게 변하고 있는지 설명하는 관점에서는 정보를 추출하고 요약하는, 즉 이해하는 도구로서 사용될 수 있다.
LDA에 대한 자세한 설명은 다음 강의에서 계속해서 진행하도록 한다.
'AI' 카테고리의 다른 글
| [NLP] hdbscan으로 키워드 클러스터링하기 (0) | 2023.03.13 |
|---|---|
| [NLP] 텍스트 내의 명사구를 추출하는 방법 (0) | 2023.02.26 |
| [NLP] OpenAI GPT-3 에서 토큰을 선택하는 방식 (feat. 샘플링) (0) | 2022.11.13 |
| [NLP/논문리뷰] How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings (0) | 2021.12.27 |
| [NLP/논문 리뷰] 위키피디아 기반 개체명 사전 반자동 구축 방법 (0) | 2021.09.23 |



