
클러스터링은 데이터 내에서 패턴과 관계를 식별하기 위한 강력한 기술입니다. 유사한 데이터 포인트를 유사성에 따라 클러스터로 그룹화하는 작업이 포함됩니다. 이번 글에서는 밀도 기반 클러스터링 알고리즘인 HDBSCAN을 사용하여 검색어 데이터를 클러스터링하는 방법에 중점을 둘 것입니다.
밀도 기반 클러스터링
계층적 클러스터링, k-means 및 밀도 기반 클러스터링을 포함하여 다양한 클러스터링 모델을 사용할 수 있습니다. 키워드 클러스터링의 경우 노이즈 및 이상값을 잘 처리할 수 있는 밀도 기반 클러스터링이 가장 적합한 선택입니다.이 알고리즘의 주요 장점은 k-means와는 달리 클러스터의 개수를 미리 지정할 필요가 없다는 점입니다.
클러스터의 정의
그렇다면 어디서부터 어디까지를 하나의 군집으로 봐야할까요? 클러스터는 일반적으로 고밀도 영역에 있고 이상값은 저밀도 영역에 있는 경향이 있다고 가정합니다. 밀도 기반 클러스터링은 고밀도 지역에 밀집된 데이터 포인트를 함께 그룹화하여 작동합니다. 즉, 클러스터를 낮은 점 밀도 영역으로 구분된 조밀한 점 영역으로 정의합니다.
X의 확률 밀도 함수인 PDF 는 X 로부터 추출한 샘플에서, 해당 지점 주변의 예상 밀도로도 해석될 수 있습니다.


DBSCAN vs HDBSCAN
가장 널리 사용되는 밀도 기반 클러스터링 알고리즘은 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)입니다. 그러나 DBSCAN은 수동 매개변수 조정이 필요하고 다양한 밀도의 클러스터를 처리하는 데 어려움이 있는 등 몇 가지 제한 사항이 있습니다.
HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)은 이러한 한계를 극복하는 DBSCAN의 확장입니다. HDBSCAN은 계층적 접근 방식을 사용하여 다양한 밀도의 클러스터를 식별하고 클러스터링을 위한 최적의 매개변수를 자동으로 결정합니다.
매개변수 선택
dbscan은 epsilon을 지정해줘야하는 반면, hdbscan은 지정할 필요가 없습니다. 또한 dbscan은 엡실론을 키울 경우 outlier는 줄어들지만 특정 군집의 크기가 매우 커지는 경향이 있습니다.
예를 들어, 세분화되어야하는 데이터가 전부 하나로 병합됩니다.
제가 분석한 데이터의 경우, dbscan을 이용하여 대출 상품들을 군집화 시도했을 때 성격이 다른 대출 상품들은 각각 분리되어야하나 각자 다른 대출 상품들이 모두 하나로 묶여버리는 현상이 발생하였습니다.
Test 1 ) DBSCAN을 사용한 경우
- 데이터 수:
5175
- 300차원 벡터, epsilon=0.6 , min_samples=2 로 설정한 경우

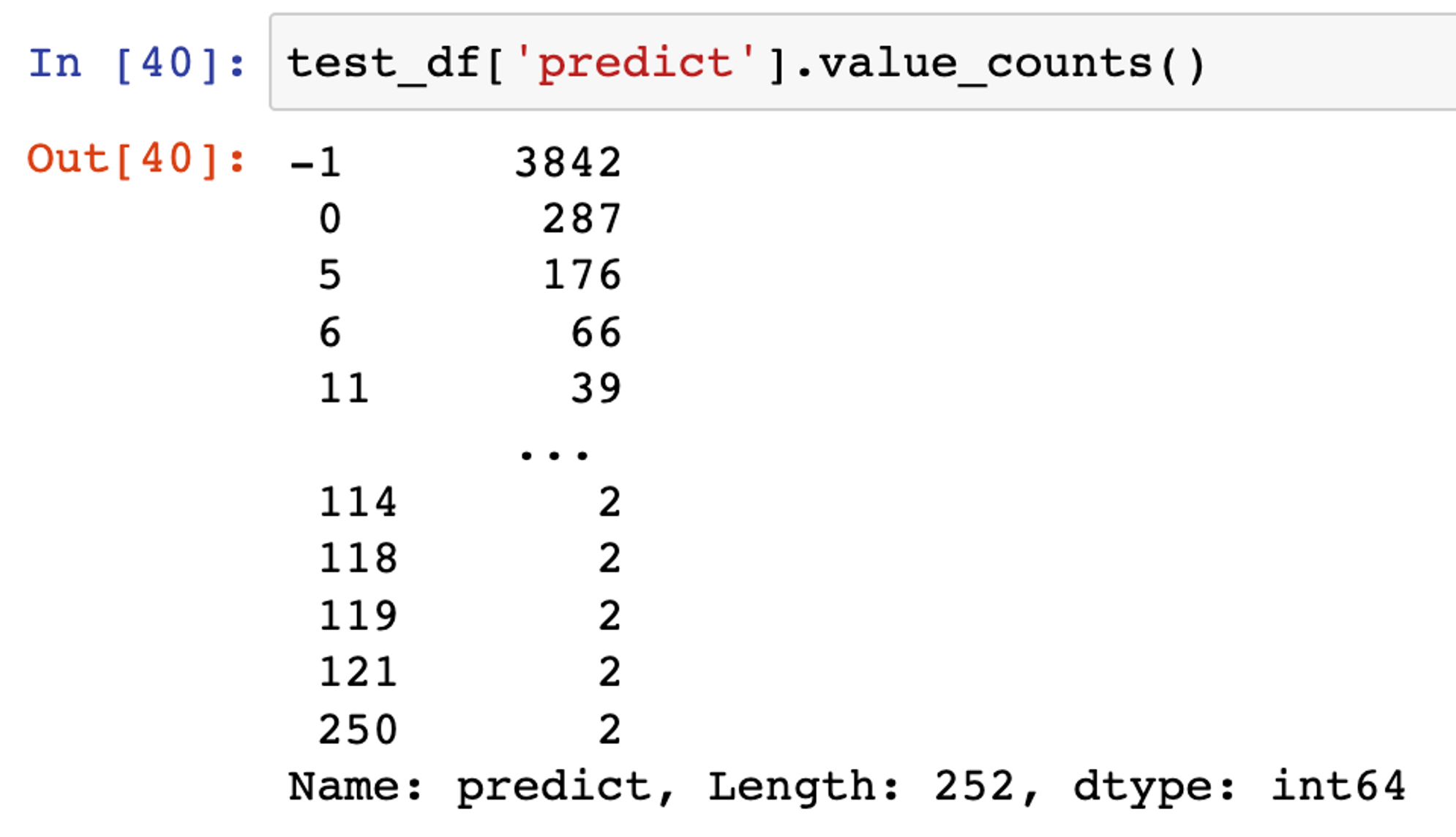
군집 내 데이터 수:
outlier: 3842
토픽번호 0: 287
토픽번호 5: 176
토픽번호 6: 66
토픽번호 11: 39
토픽번호 67: 32
토픽번호 2: 25
토픽번호 66: 19
토픽번호 12: 15
토픽번호 36: 13
토픽번호 50: 12
토픽번호 104: 11
토픽번호 48: 10
토픽번호 109: 8
토픽번호 52: 8
토픽번호 56: 7
...
이를 해결하고자 epsilon을 낮추면, 이번엔 outlier 수가 압도적으로 많아지게 됩니다.
- 300차원 벡터, epsilon=0.4 , min_samples=2 로 설정한 경우


군집 내 데이터 수:
outlier: 4979
토픽번호 23: 15
토픽번호 13: 8
토픽번호 34: 8
토픽번호 45: 6
토픽번호 44: 5
토픽번호 15: 4
토픽번호 0: 4
토픽번호 29: 4
토픽번호 27: 4
토픽번호 4: 4
토픽번호 3: 3
...Test 2 ) HDBSCAN을 사용한 경우
- 300차원 벡터, min_cluster_size=2 , min_samples=1 로 설정한 경우
만들어진 군집 중 위의 DBSCAN 결과 토픽과 거의 일치하는 군집만을 선별하여 아래와 같이 가져왔습니다. 누락된 것으로 보였던 키워드들이 각 군집에 좀 더 할당되었습니다.

또한 outlier 의 수도 4979 → 2370 으로 약 2배 줄었습니다.

군집 내 데이터 수:
outlier: 2370
토픽번호 667: 41
토픽번호 893: 19
토픽번호 850: 18
토픽번호 684: 15
토픽번호 713: 15
토픽번호 827: 15
토픽번호 784: 15
토픽번호 364: 14
토픽번호 209: 12
토픽번호 867: 12
토픽번호 666: 11
토픽번호 704: 11
토픽번호 362: 11
토픽번호 314: 10
토픽번호 879: 10
토픽번호 865: 10
토픽번호 360: 9
토픽번호 602: 9
토픽번호 814: 9
토픽번호 889: 9
토픽번호 801: 9
토픽번호 656: 8
토픽번호 902: 8
토픽번호 880: 8
토픽번호 570: 8
...hdbscan은 이런 경우를 보완할 수 있습니다. 즉, 큰 클러스터가 많은 작은 클러스터로 세분화될 수 있습니다.
어떤 알고리즘을 사용할 지는 사용하는 목적에 따라 둘 중 더 알맞는 것을 선택하면 될 것 같습니다. 큰 주제로 묶어야 할 경우 DBSCAN을, 저처럼 세분화된 주제로 분리해야 할 경우 HDBSCAN을 택할 수 있습니다.

계산 성능
또한, 계산 성능에 있어서도 HDBSCAN은 DBSCAN을 능가합니다. 아래는 200,000개의 데이터 포인트에서 HDBSCAN이 DBSCAN보다 약 2배 빠름을 보여줍니다.

결과 보정
문제점
HDBSCAN 결과 클러스터링 품질은 개선되었으나 여전히 어느 클러스터에도 속하지 않은 데이터 (outlier)의 수가 전체 데이터의 약 50%를 차지 하였습니다.
이는 HDBSCAN이 임계값을 변화시키는 동안 오래동안 살아남은 클러스터, 즉, ‘가장 안정적인 클러스터’를 선택하기 때문입니다.

이를 개선하기 위해 outlier를 가장 유사한 클러스터에 할당하는 후처리를 적용하였습니다. 해당 과정에 대해서는 다음 글에서 다루도록 하겠습니다.
'AI' 카테고리의 다른 글
| [DBSCAN] k-dist 함수 기반 엡실론 지정 방식에 대한 문제 및 한계 (0) | 2024.01.21 |
|---|---|
| Multimodal Transformer Toolkit - 텍스트 데이터에 멀티모달 데이터를 통합하기 위한 툴킷 (0) | 2023.12.10 |
| [NLP] 텍스트 내의 명사구를 추출하는 방법 (0) | 2023.02.26 |
| [NLP] OpenAI GPT-3 에서 토큰을 선택하는 방식 (feat. 샘플링) (0) | 2022.11.13 |
| [NLP/논문리뷰] How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings (0) | 2021.12.27 |



