텍스트에서 명사구가 가지는 의미
명사구는 문장에서 중요한 역할을 하며, 주어와 서술어를 이루는 요소 중 하나입니다. 또한, 명사구는 문맥에 따라 다른 의미를 가질 수 있으며, 이는 해당 문장의 전체 의미를 해석하는 데에 중요한 역할을 합니다. 텍스트 데이터에서 명사구를 추출하면 텍스트에서 다루는 주요 주제와 주제에 대한 통찰력을 얻을 수 있으며, 문서 요약, 토픽 모델링 등 다양한 자연어 처리 기술에 적용할 수 있을 것입니다.
SEO 측면에서의 활용 가능성
현재 저희 팀은 SEO(검색 엔진 최적화)를 위한 컨텐츠 작성 툴을 개발하고 있습니다. 컨텐츠가 검색 결과의 상위에 위치하려면, 검색어와 관련성이 있으면서 유용한 정보를 포함하고 있어야 합니다.
검색 결과 중 첫 번째 페이지의 결과가 바로 사람들의 검색 의도에 부합한, 사람들이 찾고 있는 정보에 가까울 것이며 그러한 상위 랭킹 페이지를 분석하여 공통적으로 많이 나오는 단어 및 명사구를 찾고자 합니다.
이렇게 찾은 완전한 문구들을 포함하도록 컨텐츠를 작성한다면 검색 엔진이 해당 컨텐츠의 의미를 더 잘 이해하게 되어 컨텐츠가 검색 결과 상위 랭킹에 올라갈 확률이 높아질 것입니다.
따라서 이번 글에서는 제가 분석 업무를 진행하며 텍스트에서 명사구를 추출한 과정을 단계별로 정리해보고자 합니다.
1. 형태소 분석
먼저 문장을 형태소 단위로 분할하고 품사를 부착해야합니다. 한국어 형태소 분석기에는 대표적으로 Okt, Mecab, Komoran, Kkma 등이 있으며, Konlpy 패키지를 이용하면 앞서말한 분석기들을 쉽게 활용할 수 있습니다.
아래는 KoNLPy를 이용한 예시 코드입니다.
from konlpy.tag import Mecab
dicpath='/usr/local/lib/mecab/dic/mecab-ko-dic'
mecab = Mecab(dicpath)
tokens = mecab.pos("형태소 분석을 수행합니다.")
print(tokens)
>>>
[('형태소', 'NNG'), ('분석', 'NNG'), ('을', 'JKO'), ('수행', 'NNG'), ('합니다', 'XSV+EF'), ('.', 'SF')]위 코드에서는 KoNLPy 라이브러리의 mecab 형태소 분석기를 이용하여 문장의 형태소를 분석한 것입니다.
형태소 분석은 구문 분석과 같이 텍스트에서 의미 있는 정보를 추출하는 데에 사용됩니다. 각각의 형태소는 문맥에 따라 다른 의미를 가지므로, 이를 분석하여 문장의 전체적인 의미를 이해하는 데에 활용할 수 있습니다.
2. 구문 분석
문장에 품사를 부착한 후에는 품사들을 조금 더 큰 단위의 묶음, 즉 구문으로 묶을 수 있습니다. 구문 분석기는 문장을 입력으로 받아 구문 구조를 분석하고, 구문 구조에 따라 명사구를 추출할 수 있게 됩니다.
구문 분석의 예시
구문 분석을 이용하여 명사구를 추출하는 예시를 살펴보겠습니다. 아래는 위의 코드와 구문 분석 라이브러리인 NLTK를 이용한 예시 코드입니다.
#! /usr/bin/python2.7
# -*- coding: utf-8 -*-
from konlpy.tag import Mecab
import nltk
# POS tag a sentence
sentence = "형태소 분석을 수행합니다."
dicpath='/usr/local/lib/mecab/dic/mecab-ko-dic'
mecab = Mecab(dicpath)
tokens = mecab.pos(sentence)
# Define a chunk grammar, or chunking rules, then chunk
grammar = """
NP: {<N.*>+} # Noun phrase
"""
parser = nltk.RegexpParser(grammar)
chunks = parser.parse(tokens)
print("# Print whole tree")
print(chunks)
print("\n# Print noun phrases only")
for subtree in chunks.subtrees():
if subtree.label()=='NP':
print(' '.join((e[0] for e in list(subtree))))
print(subtree)
>>>
# Print whole tree
(S (NP 형태소/NNG 분석/NNG) 을/JKO (NP 수행/NNG) 합니다/XSV+EF ./SF)
# Print noun phrases only
형태소 분석
(NP 형태소/NNG 분석/NNG)
수행
(NP 수행/NNG)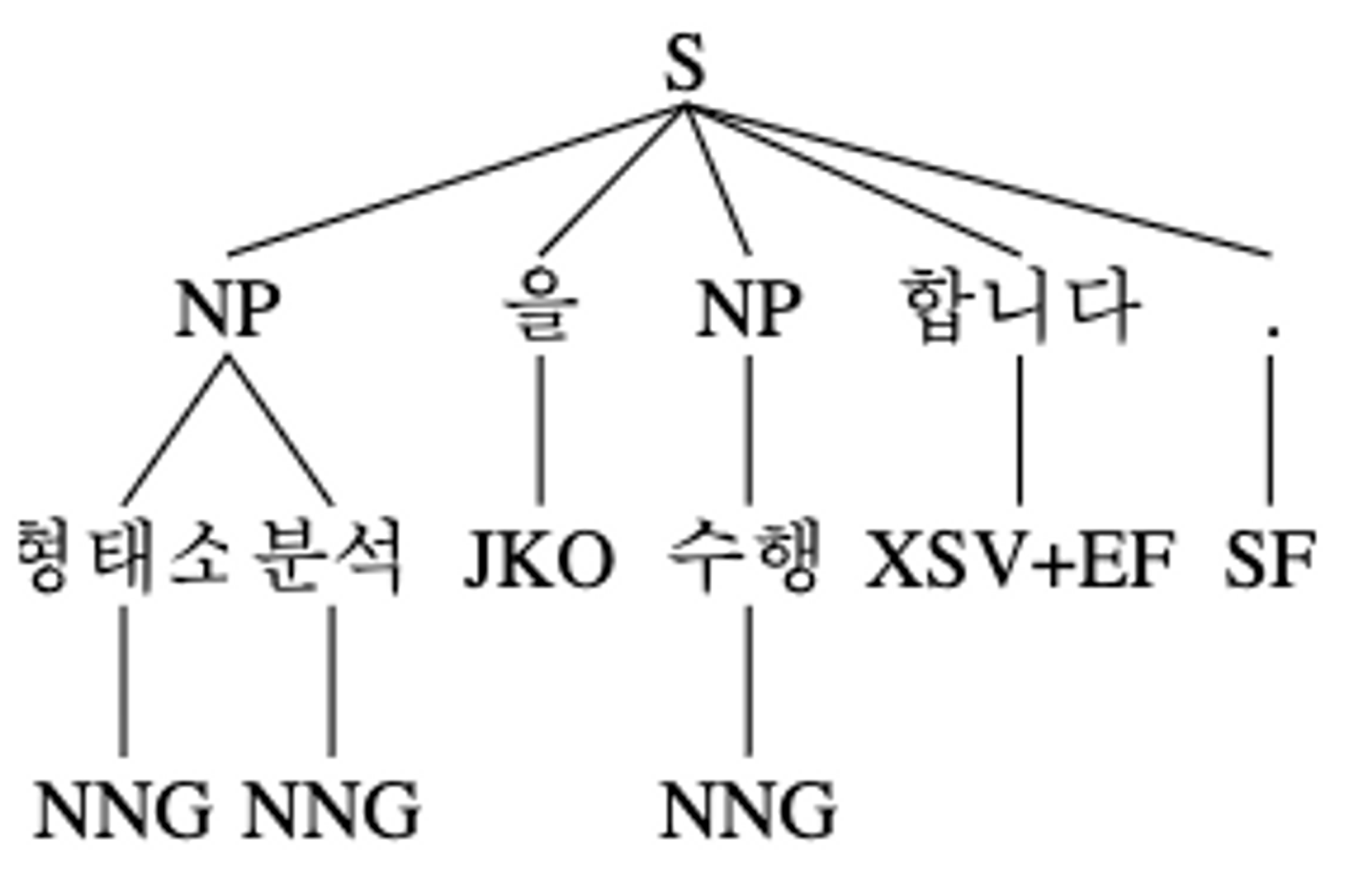
grammar 에서 구문 문법(chunk grammar)을 정의하게 됩니다. 예시에서는 명사가 1번 이상 연속적으로 등장하는 경우를 명사구(NP)로 정의하였습니다.
정규표현식에서 사용한 문자가 의미하는 바는 아래와 같습니다.
- . : 모든 문자 하나
- * : 0번 이상 반복
- + : 1번 이상 반복
- ? : 0 또는 1회
저는 mecab 토크나이저를 사용하였고, mecab에서 명사는 N으로 시작하는 태그들입니다. 따라서 N.* 는 N으로 시작하며 뒤에 아무 문자나 하나가 0번 이상 반복되는 태그들을 허용한다는 뜻입니다.
그 태그들의 뒤에 + 가 붙었다는 것은 명사 태그가 1번이상 반복되는 것을 명사구로 지정함을 의미합니다.
형태소 분석기의 종류에 따라 문법 규칙은 바뀌어야할 것입니다. mecab의 품사 태그는 여기에서 확인 할 수 있으며, 좀 더 자세히 설명된 글도 있습니다.
예시에서는 간단하게 한 가지 패턴으로 정의했지만, 우리가 문장에서 사용하는 명사구는 예시에서처럼 간단하게 하나의 패턴으로 정의되지는 않을 것입니다.
명사구의 패턴은 어떻게 정의해야 할까요?
명사구 패턴은 각각의 텍스트에 맞게 유연하게 정의되어야 합니다. 일반적인 패턴으로는 정규 표현식을 이용하여 명사 앞에 나오는 한글자 이상의 형용사와 명사의 조합을 찾는 것이 가능합니다. 또한, 명사와 명사 사이에 등장하는 조사를 이용해서 명사구를 추출하는 방법도 있습니다.
최근에는 딥러닝을 이용한 자연어 처리 기술이 급부상하면서, 구문 분석과 형태소 분석을 결합하여 명사구를 추출하는 방법도 있습니다. 예를 들어, BERT, GPT 등의 모델을 이용하여 텍스트를 분석하면서 명사구를 추출하는 방법이 있습니다.
그러나 저는 일단은 프로토타이핑으로 분석을 수행하는 단계이기 때문에 문장에서 자주 쓰이는 명사구의 패턴을 확인하고 그 패턴으로 구문 문법을 지정하였습니다.
제가 정의한 패턴은 아래와 같습니다.
grammar = r"""
Num: {<SN|NR|MM>+<NNBC>?} # 수 + 단위
N1: {<NNG|NNP|SL>} # 명사 or 외국어
N2: {<XPN><N1>} # 체언접두사 + 명사 / 최상위, 비과학, 신제품 ...
N3: {<N1|N2>+<XSN>+} # 명사 + 명사 파생 접미사 / 표준화, 문화적, 식물성...
NN: {<N1|N2|N3>} # 명사 케이스들의 집합
NP_3: {<NN>+<VV><ETN>} # 명사 + 동사 + 명사형 전성 어미 / ~ 만들기, ~하기
NP_2: {<NN>+<VV><ETM><NN>*} # 명사 + 동사 + 관형형 전성 어미 + 명사 / ~하는 방법, ~먹는 시간..
NP_1: {<NN|Num|SY>+} # 명사 or 숫자 or 특수문자 반복
"""해당 패턴으로 정해지게 된 컨텍스트에 대해서는 다음 글에서 작성하도록 하겠습니다. 이렇게 구문 문법을 정의한 후, tree를 생성 합니다. 이 때, 반복문으로 트리를 순회하며 명사구를 추출하고자 할 경우 명사구의 자식들은 건너뛰고 최상위 부모만을 결과값에 추가해야 합니다.
예를 들어 아래와 같은 문장이 있을 때, 제가 추출하고자 하는 명사구는 식품별 칼로리표 만들기 이지만 트리를 순회할 때는 모든 자식들을 방문하게 됩니다.
text ="식품별 칼로리표 만들기를 해볼까요?"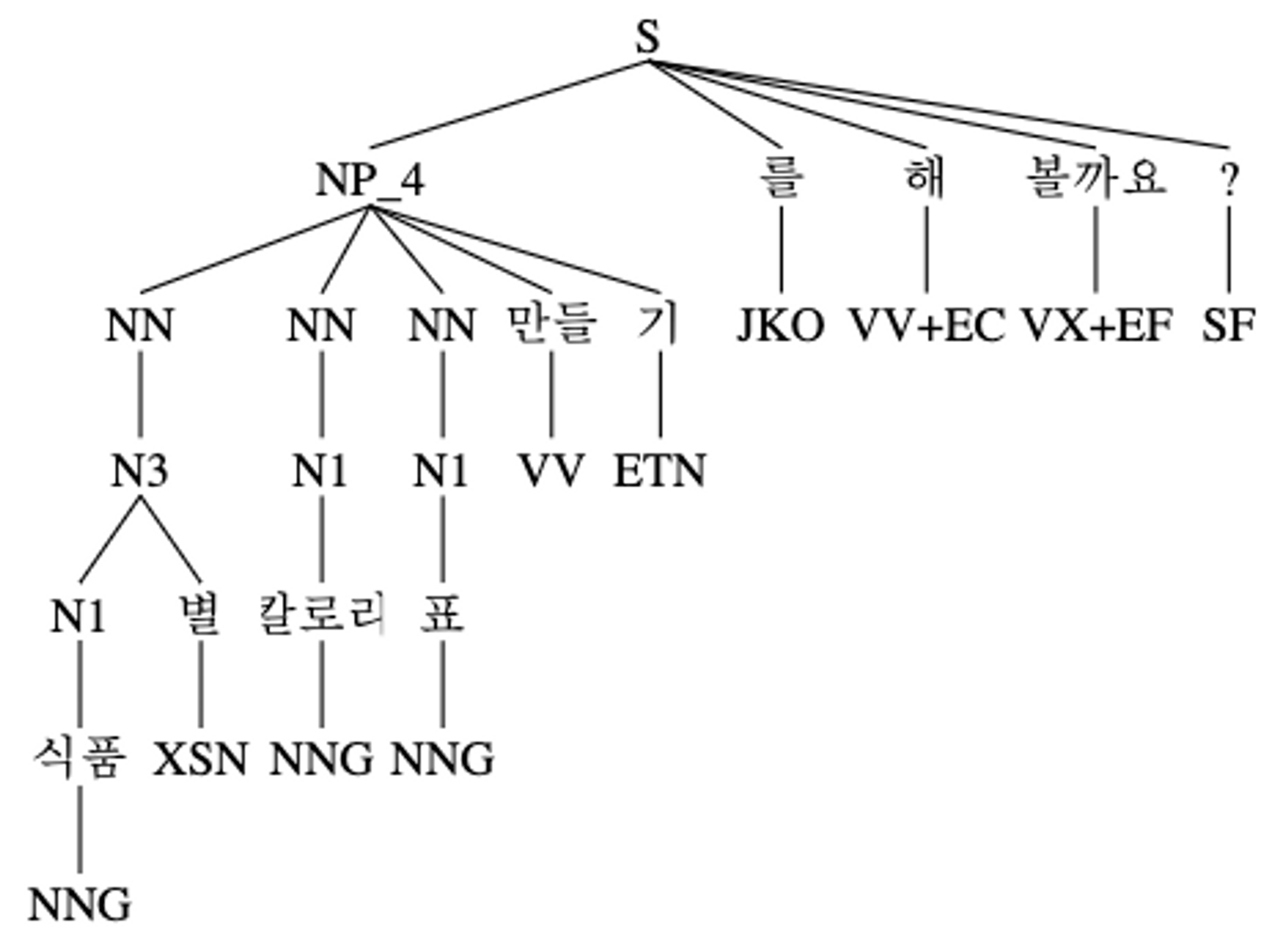
깊이: 1
노드: (NP_4
(NN (N3 (N1 식품/NNG) 별/XSN))
(NN (N1 칼로리/NNG))
(NN (N1 표/NNG))
만들/VV
기/ETN)
Label: NP_4
Leaves: [('식품', 'NNG'), ('별', 'XSN'), ('칼로리', 'NNG'), ('표', 'NNG'), ('만들', 'VV'), ('기', 'ETN')]
-----------------------------
깊이: 2
노드: (NN (N3 (N1 식품/NNG) 별/XSN))
Label: NN
Leaves: [('식품', 'NNG'), ('별', 'XSN')]
-----------------------------
깊이: 3
노드: (N3 (N1 식품/NNG) 별/XSN)
Label: N3
Leaves: [('식품', 'NNG'), ('별', 'XSN')]
-----------------------------
깊이: 4
노드: (N1 식품/NNG)
Label: N1
Leaves: [('식품', 'NNG')]
-----------------------------
깊이: 2
노드: (NN (N1 칼로리/NNG))
Label: NN
Leaves: [('칼로리', 'NNG')]
-----------------------------
깊이: 3
노드: (N1 칼로리/NNG)
Label: N1
Leaves: [('칼로리', 'NNG')]
-----------------------------
깊이: 2
노드: (NN (N1 표/NNG))
Label: NN
Leaves: [('표', 'NNG')]
-----------------------------
깊이: 3
노드: (N1 표/NNG)
Label: N1
Leaves: [('표', 'NNG')]
-----------------------------따라서 저는 순회 시 높이가 1일 때만, 즉 최초의 부모 명사구인 것만 추출하도록 하여 명사구 리스트에는 의도한 하나의 구만 추출되게 하였습니다.
print(noun_phrases)
>>>
['식품별 칼로리표 만들기']전체 코드
전체 코드는 아래와 같습니다.
import konlpy
from konlpy.tag import Mecab
import nltk
from nltk.chunk import RegexpParser
# Define a chunk grammar for RegexpParser
grammar = r"""
Num: {<SN|NR|MM>+<NNBC>?} # 수 + 단위
N1: {<NNG|NNP|SL>} # 명사 or 외국어
N2: {<XPN><N1>} # 체언접두사 + 명사
N3: {<N1|N2>+<XSN>+} # 명사 + 명사 파생 접미사 / 표준화, 문화적, 식물성...
NN: {<N1|N2|N3>} # 명사 케이스들의 집합
NP_4: {<NN>+<VV><ETN>} # 명사 + 동사 + 명사형 전성 어미 / ~ 만들기, ~하기
NP_3: {<NN>+<VV><ETM><NN>*} # 명사 + 동사 + 관형형 전성 어미 + 명사 / ~하는 방법, ~먹는 시간..
NP_1: {<NN|Num|SY>+} # 명사 or 숫자 or 특수문자 반복
"""
# Initialize RegexpParser with the chunk grammar
parser = RegexpParser(grammar)
# Parse the tokens to obtain a parse tree
text ="식품별 칼로리표 만들기를 해볼까요?"
dicpath='/usr/local/lib/mecab/dic/mecab-ko-dic'
mecab = Mecab(dicpath)
tokens = mecab.pos(text)
tree = parser.parse(tokens)
_tokens = spanned_tokens(tokens)
# Extract the noun phrases from the parse tree
noun_phrases = []
i = 0
leaves_list = get_leaves_list(tree)
for sublist in leaves_list:
print(f'서브리스트: {sublist}')
for j in range(i, len(_tokens)):
if sublist == [(word, pos) for word, pos, span in _tokens[j:j+len(sublist)]]:
print(f"Match found at position {j}")
matched = _tokens[j:j+len(sublist)]
noun_phrase = concat_tokens(matched)
noun_phrases.append(noun_phrase)
break
i = j + len(sublist)
print()
# Print the extracted noun phrases
print(noun_phrases)위에서 사용된 util 함수들은 아래와 같으며, 향후 부연 설명을 추가로 작성하도록 하겠습니다.
def spanned_tokens(tokens):
updated_tokens = []
i = 0
for token in tokens:
while i <= len(text):
word, pos = token
if text[i:i+len(word)] == word:
start_index = i
end_index = start_index + len(word)
updated_tokens.append((word, pos, (start_index, end_index)))
i += len(word) - 1
break
i += 1
return updated_tokens
def get_leaves_list(tree):
leaves_list = []
depth = 0
def getNodes(parent, depth):
depth += 1
for node in parent:
if type(node) is nltk.Tree:
print(f"깊이: {depth}")
print(f"노드: {node}")
print()
print("Label:", node.label())
print("Leaves:", node.leaves())
print("-----------------------------\n")
if depth == 1:
leaves_list.append(node.leaves())
getNodes(node, depth)
depth = 1
getNodes(tree, depth)
return leaves_list
def concat_tokens(subset):
result = ""
prev_end = None
for word, tag, span in subset:
if not prev_end or prev_end == span[0]:
result += word
prev_end = span[1]
else:
whitespace_cnt = span[0] - prev_end
result += " " * whitespace_cnt + word
prev_end = span[1]
return result결론
이번 글에서는 구문 분석을 이용하여 텍스트 내의 명사구를 추출하는 방법에 대해 알아보았습니다. 현존하는 모든 케이스를 반영한 완벽한 방식이라고 할 수는 없습니다. 그러나 사용하고자 하는 목적에 맞게 패턴을 정의하고 그에 따른 결과를 도출하는 과정을 좀 더 쉽게 설명하고자 했으며 이 글이 도움이 되었다면 좋겠습니다.
'AI' 카테고리의 다른 글
| Multimodal Transformer Toolkit - 텍스트 데이터에 멀티모달 데이터를 통합하기 위한 툴킷 (0) | 2023.12.10 |
|---|---|
| [NLP] hdbscan으로 키워드 클러스터링하기 (0) | 2023.03.13 |
| [NLP] OpenAI GPT-3 에서 토큰을 선택하는 방식 (feat. 샘플링) (0) | 2022.11.13 |
| [NLP/논문리뷰] How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings (0) | 2021.12.27 |
| [NLP] 텍스트 마이닝의 개념과 전체적인 프로세스에 대하여 (0) | 2021.12.06 |



