Apache Arrow란?
서로 다른 데이터 인프라가 서로 간의 데이터 공유를 위해 API를 이용할 때 발생하는 문제점 중 하나는 직렬화와 역 직렬화의 오버헤드가 너무 높다는 것이다. 이는 애플리케이션 성능의 병목을 초래한다.
Arrow는 언어, 플랫폼과 상관없이 메모리 상에서 컬럼 구조로 데이터를 정의하여, CPU와 GPU에서 메모리를 빠르게 읽고 쓸 수 있도록 한다.
직렬화(Serialization)란?
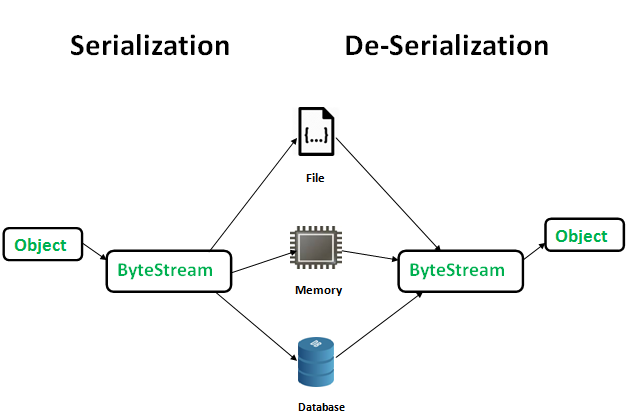
객체를 저장하거나 메모리, 데이터베이스 혹은 파일로 옮길 때 필요한 것이 직렬화이다. 직렬화란 객체를 바이트 스트림으로 바꾸는 것, 즉 객체에 저장된 데이터를 스트림에 쓰기(write) 위해 연속적인(serial) 데이터로 변환하는 것이다.
직렬화의 주된 목적은 객체를 상태 그대로 저장하고 필요할 때 다시 생성하여 사용하는 것이다.
예시) 통화 상대방에게 강아지의 특성을 설명할 때
- 강아지의 모든 특성을 담은 객체를 생성해서 직렬화 한다.
{ "name":"Rex", "age":5, "favourite_food": pedigree_choice_cuts, "favourite_game": fetch_ball, "favourite_hobby": wagging_tail }
- 상대방은 ByteStream을 역직렬화 하여 객체를 다시 생성할 수 있다.

Zero-Copy 직렬화
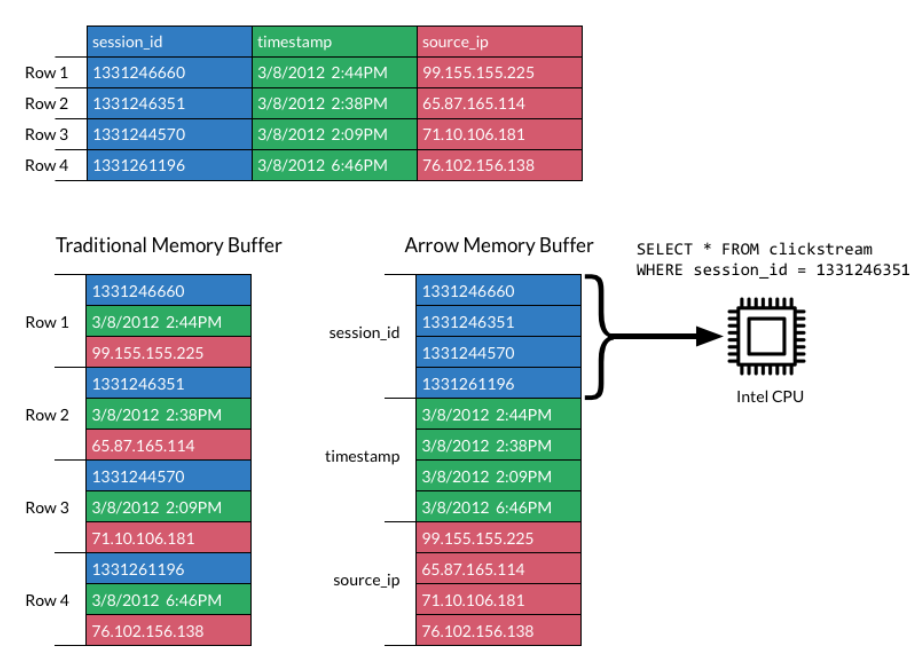
Apache Arrow는 행(Row) 기반이 아닌 컬럼 기반의 인메모리 포맷으로 Zero-Copy 직렬화를 수행한다.
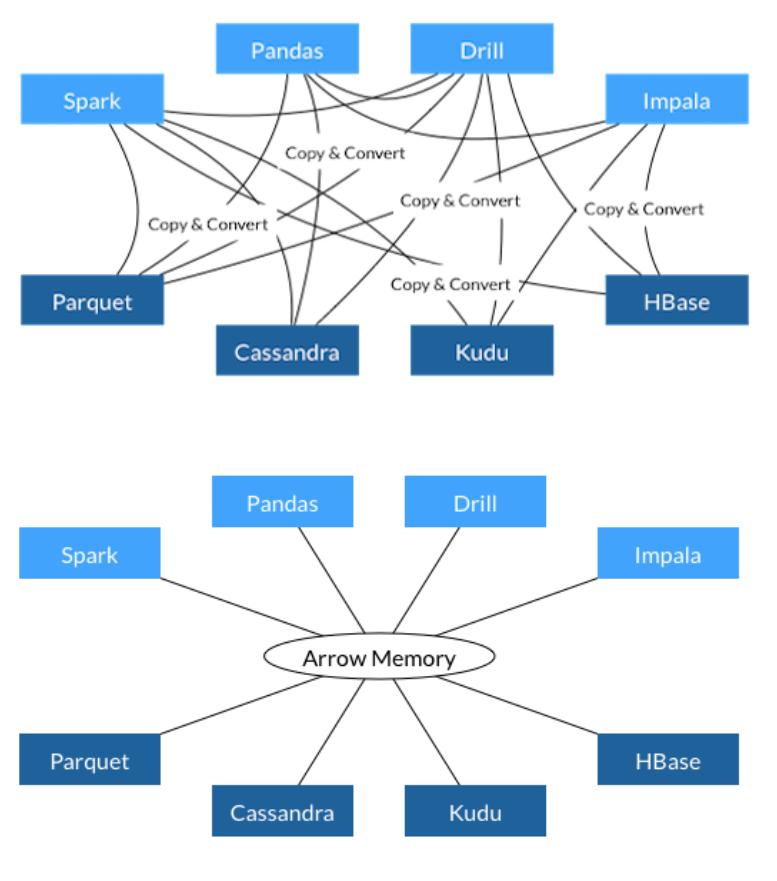
기존에는 서로 다른 데이터 인프라가 데이터를 공유하기 위해서는 serialization/deserialization이 필요했다.
즉 위의 강아지 예시처럼, python에서 정의한 특정 객체를 다른 플랫폼으로 보내 데이터를 공유하려면 공통의 형식으로 바꿔주는 단계가 있어야 했고, 바뀐 형태로 도착하면 다시 그 플랫폼에 맞는 형태로 바꿔주는 deserialization 또한 필수였다.
이러한 단계는 방대한 데이터가 오가는 상황에서 오버헤드를 초래하게 된다.
그래서 직렬화 과정을 없애버리자는 목적으로 Apache Arrow와 같은 zero-copy serialization framework가 생기게 되었다.
이런 프레임워크들은 serialization step을 없애기 위해 객체를 가지고 작업하는 대신 직렬화된 데이터 자체를 가지고 작업한다. 이렇게 하면 당연히 네트워크를 통해 전송될 때에도 serialization 을 거치지 않기 때문에 훨씬 효율적이며 데이터를 받는 쪽에서도 deserialization을 하지 않아도 된다.
양쪽에서 공통 형식인 Arrow를 쓰면 어떤 레코드를 읽을 때 어디서 부터 어디까지 읽을 지 알 수 있게 된다.
Ref.
https://stackoverflow.com/questions/633402/what-is-serialization
'Big Data > Spark' 카테고리의 다른 글
| [Spark] 하둡 hdfs 파일 하나로 합쳐 local에 내려받기 (getmerge, *.gz파일) (0) | 2021.12.06 |
|---|---|
| [Spark] SQL - 두 컬럼을 병합하여 새로운 Dataframe 만들기 (0) | 2021.10.03 |
| [Spark] SQL - explode()를 사용하여 list 형태의 Row 분리하기 (0) | 2021.10.03 |


