1. 압축파일이 아닐 경우
hdfs에 나누어 저장되어 있는 파일들을 합쳐서 로컬로 받고 싶은 경우에는 -getmerge 명령어를 사용하고, 파티션들이 저장되어 있는 상위 디렉토리를 hdfs 경로로 준다.
$ hdfs dfs -getmerge [hdfs 경로] [내려받을 local위치]
Ex)

위의 경우에는 20211204_161503_442837 디렉토리 내에 파일들이 나누어져 저장되어있기 때문에 해당경로까지를 첫 번째 인자로 넣어준다.
$ hdfs dfs -getmerge /user/nauts/warehouse/anchor_set/wiki/all/20211204_161503_442837 [local위치]2. 압축 파일일 경우
하지만 나누어져있는 파일이 다음과 같이 .gz와 같은 압축 파일인 경우에는 -getmerge를 사용할 수 없다.
이때 목적에 따라 명령어를 다르게 쓴다.

2-1. -getmerge와 같은 결과를 위해 전체 파일을 모두 내려받고자 하는 경우
이럴 경우에는 두 단계로 수행한다.
1. 먼저 파일을 read한 후 coalesce 혹은 repartition으로 파티션 수를 1로 설정하여 새 hdfs 경로에 save한다.
2. 해당 파일은 이제 압축파일이 아니므로 1번의 getmerge를 사용하여 로컬에 내려받는다.
df = spark.read.json("[hdfs 경로 1]")
df.coalesce(1).write.format("json").mode("overwrite").option(
"header", "true").save("[hdfs 경로 2]")
2-2. 하나의 파일만 확인용으로 내려받고자 하는 경우
이때는 -text 명령어를 이용하며, hdfs경로는 상위 디렉토리까지가 아닌 개별 파일명까지 전체 경로를 넣는다.
$ hdfs dfs -text [hdfs 경로] > [내려받을 local위치]Ex)
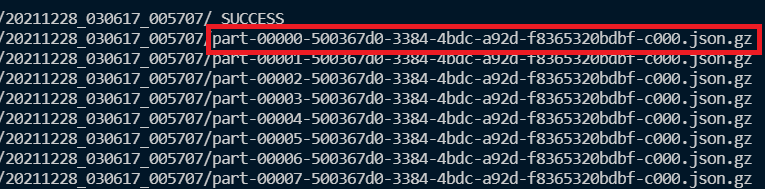
$ hdfs dfs -text /user/nauts/warehouse/anchor_set/wiki/all/20211228_030617_005707/part-00000-500367d0-3384-4bdc-a92d-f8365320bdbf-c000.json.gz > [local 위치]
Ref.
'Big Data > Spark' 카테고리의 다른 글
| [Spark] Apache Arrow란? (Zero-Copy 직렬화에 대하여) (0) | 2021.12.30 |
|---|---|
| [Spark] SQL - 두 컬럼을 병합하여 새로운 Dataframe 만들기 (0) | 2021.10.03 |
| [Spark] SQL - explode()를 사용하여 list 형태의 Row 분리하기 (0) | 2021.10.03 |


