📝 9월 13일 (월)
▪️ MediaWiki
미디어위키 텍스트 원문 보기
- 원래 주소 뒤에 action=raw를 추가
- https://도메인/wiki/글제목?action=raw
Ex) 위키백과의 삼성 갤럭시 버즈 페이지

?action=raw를 추가하여 원문 확인한 결과
https://ko.wikipedia.org/wiki/삼성_갤럭시_버즈?action=raw

Ref.
https://zetawiki.com/wiki/미디어위키_텍스트_원문_보기
wiki extractor에서 개체명의 language템플릿을 보존하여 text 추출하기
wiki extractor를 이용하여 plain text 추출 시 개체명의 외국어 명이 담긴 language template은 제거되어버리는 issue가 있었다.
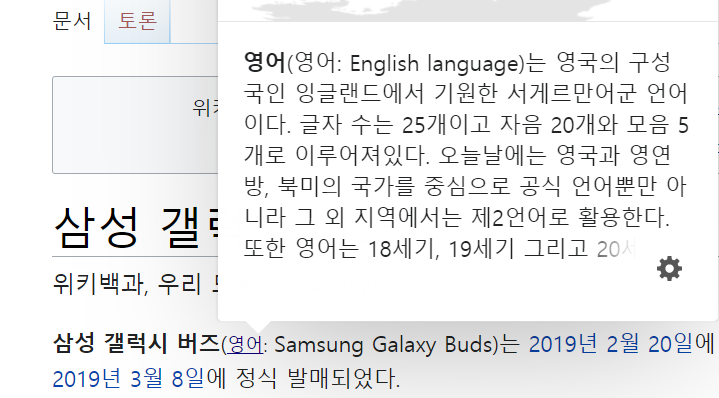
삼성 갤럭시 버즈 페이지의 본문을 추출해서 확인해보면 아래와 같이 나오게 된다.
삼성 갤럭시 버즈( ) 는 2019년 2월 20일에 ....
따라서 wiki extractor의 내부 코드 중 template을 제거하는 부분을 수정하여 language 템플릿이라면 남겨두도록 하였다. (해당 과정은 게시글로 작성 예정)
📝 9월 14일 (화)
▪️ ElasticSearch 색인(index)명 변경
rename은 불가능하고 대신 색인을 복사함으로써 이름을 교체한다.
만약 인덱스 INDEX_A 를 INDEX_B 로 이름을 바꾸고 싶다면 아래 순서대로 진행한다.
- 인덱스 복사
POST _reindex
{
"source": {
"index": "INDEX_A"
},
"dest": {
"index": "INDEX_B"
}
}2. 기존 인덱스명 삭제
DELETE INDEX_A▪️ Python
변수의 타입(type)을 비교하는 방법
if str(type(text)) == "<class 'str'>":
return text▪️ Boj 알고리즘 단계별 - 기본수학 1
📝 9월 15일 (수)
▪️ Python unittest
unittest (단위테스트) 로 모듈 테스트하기
PR을 보냈을때 리뷰어로부터 유닛테스트를 작성하여 모듈이 정상 작동하는지 확인해달라는 요청을 받았다.
단위 테스트란?
모듈 또는 응용 프로그램 내의 개별 코드 단위가 예상대로 작동하는지 확인하는 반복 가능한 활동이다.
|
+---root
|
+---lib
| | calculator.py
|
+---test
| __init__.py
| test_calculator.pyCalculator.py 모듈을 테스트하고자 할 때 위와 같이 test 디렉토리를 만들고 해당 디렉토리를 모듈로 인식하기 위해 __init__.py 파일을 생성한다.
그리고 테스트 내용이 있는 test_calculator.py 파일을 생성한다.
# calculator.py 파일
class Calculator:
def __init__(self):
print('\nCalculator init')
def add(self, x, y):
return x + y
def multiply(self, x, y):
return x * y
def __del__(self):
print("Calculator delete")# test_calculator.py 파일
import unittest
import inspect
from lib.calculator import Calculator
class CalculatorTest(unittest.TestCase):
"""1자리 숫자 연산을 확인한다"""
def setUp(self):
self.cal = Calculator()
def test_plus(self):
assert self.cal.add(3, 4) == 7
print(f'{inspect.stack()[0][3]}() is pass')
def test_multiply(self):
assert self.cal.multiply(3, 4) == 12
print(f'{inspect.stack()[0][3]}() is pass')
def tearDown(self):
del self.cal규칙
1. unittest.TestCase를 상속받은 클래스를 만든다
2. 보통 클래스의 init 함수 대신 unittest는 setUp함수를 사용한다.
3. 함수명은 test로 시작해야한다.
4. 테스트는 프로젝트의 최상위 디렉토리에서 실행한다. (위의 예시에서는 root)
$ cd root
$ python -m unittest test.test_calculator
Ref.
https://docs.python.org/3/library/unittest.html
▪️ Boj 알고리즘 단계별 - 기본수학 1
📝 9월 16일 (목)
▪️ NLP paper reading
텍스트 마이닝 기법을 적용한 뉴스 데이터에서의 사건 네트워크 구축
💡 논문에서 참고한 두 가지 해결 목표
1. 뉴스기사의 고유명사 및 합성명사 보존을 위한 분리된 토큰 결합
2. 동일한 인물이나 기관, 대상이 여러 가지 형태의 다른 표현으로 작성되는 이형동의어 통합
1. PMI를 활용한 토큰 결합
형태소 분석기의 문제
형태소 분석기를 통하여 자동 추출한 명사 토큰에서는 뉴스 기사가 가지고 있는 다양한 고유명사 및 합성명사가 제대로 반영되지 않았는데, 이는 형태소 분석기에서 제공하는 사전에 이러한 단어들이 포함되어 있지 않기 때문이다.

또한 단순히 n-gram 기법 만으로는 잘못 분할된 토큰을 병합하는 데 한계가 있다.
💡 해결방안
- 점별 상호정보량(Pointwise Mutual Information, 이하 PMI) 를 이용
- PMI: 두 토큰이 함께 등장하는 정도를 정보량을 바탕으로 계산한 지수
토큰 결합 알고리즘
- 2개, 3개의 토큰의 PMI와 NPMI(Normalized PMI) 를 구한다.
- 길이 3의 토큰 쌍 목록을 바탕으로 길이 4이상인 토큰 쌍 후보 생성
- 생성된 토큰 쌍 후보에서 부분적으로 겹치는 것을 제거하고 유의미한 것만 남겨 후보를 선별


2. Word2Vec을 활용한 이형동의어 통합
💡해결방안
- Word2Vec과 글자 단위 자카드(Jaccard) 유사도를 이용하여 이형동의어 목록을 자동으로 추출하여 통합 하는 방법을 사용
- 위에서 분할된 토큰을 결합한 과정을 거친 텍스트 데이터를 사용
- word2vec의 skip-gram 알고리즘으로 단어의 의미적 유사도를 계산
- 자카드 유사도의 변형을 사용하여 두 단어의 형태적 유사도를 계산
- 의미적 유사도와 형태적 유사도를 혼합하는 비율인 p를 설정하고 클러스터링을 통해 이형동의어 통합
📝 9월 17일 (금)
▪️ Python
requests.exceptions.ConnectionError: Max retries exceeded with url 에러
postman이나 터미널에서 curl command를 보냈을 때는 api가 정상적으로 동작하였으나 python에서 실행 시 요청이 거절당하였다.
requests.exceptions.ConnectionError: HTTPConnectionPool(host='----', port=----): Max retries exceeded with url: /mediawiki/index.php?title=Tesla&redirect=yes (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7ff0c67e8220>: Failed to establish a new connection: [Errno 110] Connection timed out'))
거의 대부분의 해결책은 아래와 같이 try except문을 걸어 time.sleep을 사용하여 일정 시간 텀을 주며 api를 호출하라고 하였지만 내 코드에서는 해결되지 않았다.
try:
result = getData() #-- getData 함수는 requests.get()
except:
time.sleep(2)
result = getData()💡 해결
왜 해결되었는지는 밝혀낼 수 없었지만 처음에 request를 보내는 url에서 도메인 명을 사용했었는데, 요청이 거절당하자 IP주소로 바꾸었더니 실행이 되었다.
하지만 다음날 같은 요청을 수행하자 거절당했고 다시 도메인명으로 바꾸었더니 실행되었다.
url = http://도메인명:포트번호
- 도메인명 (거절됨)
- IP주소 (실행됨)
- IP주소 (거절됨)
- 도메인명 (실행됨)
해당 원인을 밝혀봐야겠다.
📝 9월 19일 (일)
▪️ Boj 알고리즘 단계별 - 기본수학 1
문제 설명
- 임의의 층과 호수를 입력받으면 해당 호실에 사는 사람의 수를 입력하는 문제
- 해당 호실 사람의 수는 한층 아래 1호부터 같은 호수까지의 사람 수의 합

가장 난항을 겪은 문제다. 재귀함수를 써서 풀어보려했지만 실패하였고 다소 나이브한 방식으로 배열을 생성하며 합계를 구하였다가 시간초과가 나왔다.
❌ 실패한 코드
def list_generator(n):
n_list = []
for i in range(1, n+1):
n_list.append(i)
return n_list
def find(k, n):
n_list = list_generator(n)
for i in range(k-1, 0, -1):
j = 0
while True:
push_list = list_generator(n_list[j])
n_list[j:j+1] = push_list
j = j+len(push_list)
# print(j)
# print(n_list)
if j == len(n_list):
break
return sum(n_list)
if __name__ == "__main__":
T = int(input())
for i in range(T):
k = int(input())
n = int(input())
people = find(k, n)
print(people)k(층수) =2 이고 n(호수) =3인 Case일때 층수만큼 과정을 진행한다.
- k==1
- n_list = [1, 2, 3]
- k==0
- n_list = [ [1] , [1, 2] , [1, 2, 3] ]
⇒ 최종적으로 남은 n_list내의 원소들을 합하면 거주하는 사람 수가 나온다.
💡 솔루션 코드
t = int(input())
for _ in range(t):
floor = int(input()) # 층
num = int(input()) # 호
f0 = [x for x in range(1, num+1)] # 0층 리스트
for k in range(floor): # 층 수 만큼 반복
for i in range(1, num): # 1 ~ n-1까지 (인덱스로 사용)
f0[i] += f0[i-1] # 층별 각 호실의 사람 수를 변경
print(f0) # 프린트문을 추가
print(f0[-1]) # 가장 마지막 수 출력
나는 위층에서 아래층으로 내려가며 계산하는 방식이었다면, 솔루션 코드는 0층부터 더해가며 k층까지 올라가는 방식이다.
또한 층마다 합계를 구하고 층별 호실의 사람 수(f0 배열)를 교체하기 때문에 메모리 낭비도 없게 된다.
f0 배열이 바뀔때 마다 출력해보면 다음과 같다.
[1, 3, 6, 10, 15]
[1, 4, 10, 20, 35]
[1, 5, 15, 35, 70]
[1, 6, 21, 56, 126]
126'WIL (Weekly I Learned)' 카테고리의 다른 글
| [TIL] 백준 13300번: 방 배정 (Python) - 시간 복잡도 O(N)으로 풀기 (0) | 2023.01.02 |
|---|---|
| [WIL] 2021년 9월 넷째 주/ 10월 첫째 주 WIL (0) | 2021.10.15 |
| [WIL] 2021년 9월 둘째 주 WIL (0) | 2021.09.13 |
| [WIL] 2021년 9월 첫째 주 WIL (0) | 2021.09.06 |



