개요
Amazon이 제안한 Recformer는 기존의 추천 시스템에서의 고질적인 문제인 cold-start 문제에 대한 대안으로 아이템의 id를 사용하는 것이 아닌 아이템을 설명하는 텍스트만을 사용한 방법에 대한 논문입니다. 기본 아이디어는 유저의 과거 아이템 선택에 대한 텍스트 시퀀스를 입력으로 받아 언어 이해도를 기반으로 다음 아이템을 예측하도록 합니다. 이때, Bert류의 양방향 트랜스포머 언어모델을 동일하게 사용하면서도 임베딩에서 몇 가지 변화를 주어서 아이템간의 구분이 가능하게 하였습니다.
언어 이해와 추천을 모두 고려하기 위해 사전학습 과정은 (1)마스크 언어 모델링과 (2)아이템-아이템 contrastive learning 두 가지 태스크로 이루어집니다.
해당 모델의 학습 및 파인튜닝 관련 코드도 github 레포지토리에서 확인할 수 있습니다.
순차적 추천이란
추천 시스템에서도 사용자의 과거 이력을 통한 순차적 추천을 모델링하는 부분에 초점을 맞춘 방식입니다.
순차 추천이란?
사용자 행동의 시간적 역학을 순차적 데이터에서 학습하고 사용자가 나중에 원하는 항목을 예측하는 작업입니다.
기존의 콘텐츠 기반 필터링 / 협력 필터링 / 딥러닝을 활용한 추천시스템은 사용자의 과거 아이템 선택 정보가 동일하게 중요하다는 가정에서 출발합니다. 그러나 실제로 사용자가 선택을 할 때에는 과거 구매 정보가 동일하게 중요하지 않습니다.

주로 선택하던 아이템과 다른 아이템을 가장 최근에 선택할 경우 위의 알고리즘으로는 이에 대한 충분한 설명이 부족합니다. 협력 필터링 등 보편적으로 사용되는 추천시스템 모델에서는 사용자가 주로 선택하던 아이템을 추천하게 됩니다.

따라서 등장한 것이 순차적 추천입니다. 사용자의 선호도, 관심은 끊임없이 변화하고 발전한다는 아이디어에서 시작하며, 과거 행동에서 유의미한 순차적인 패턴을 찾고 최근 아이템에 더 집중하여 이를 기반으로 가장 선호할 다음 아이템을 추천하도록 합니다.
순차 추천 시스템에 대한 더 자세한 설명은 Introduction to Sequential Recommender Systems 영상을 참고하면 좋을 것 같습니다. 위의 이미지 또한 해당 영상 자료에서 인용하였음을 밝힙니다!
기존 순차적 추천 시스템의 문제점
- BERT4Rec
- youtube 설명 영상
- Bert의 구조를 사용해서 유저의 아이템 항목 시퀀스를 학습하도록 함
- 학습셋의 도메인, 유저, 아이템이 그대로 유지되지 않고 매번 바뀐다. (cold-start 문제)
대안: Text is all you need
- 따라서 텍스트로 아이템의 시퀀스를 잘 표현할 수만 있다면 cold-start 문제 없이 순차적 추천 시스템을 잘 구축할 수 있을 것입니다.
- 아이템 시퀀스를 텍스트로 표현하는 방식은 먼저 아래와 같이 아이템 속성의 key-value를 단순히 순차적으로 이어붙이는 것입니다.
- 그리고 해당 구조를 언어 모델이 이해할 수 있는 형태로 변환해주어야합니다.


모델 구조
모델 입력은 사용자의 아이템 시퀀스를 최신순으로 정렬한 토큰의 리스트 𝑋 = {[CLS],𝑇𝑛,𝑇𝑛−1,...,𝑇1} 입니다.
입력을 아래 임베딩 과정을 거친 후, Transformer 모델로부터 특성벡터를 추출합니다. 논문에서는 계산효율성을 위해서 Longformer 모델을 채택하였지만 Bert와 같은 다른 양방향 트랜스포머 모델에도 사용할 수 있습니다.
다른 언어 모델과 유사하게 첫 번째 토큰h[CLS] 의 표현이 시퀀스를 대표하는 표현으로 사용됩니다.
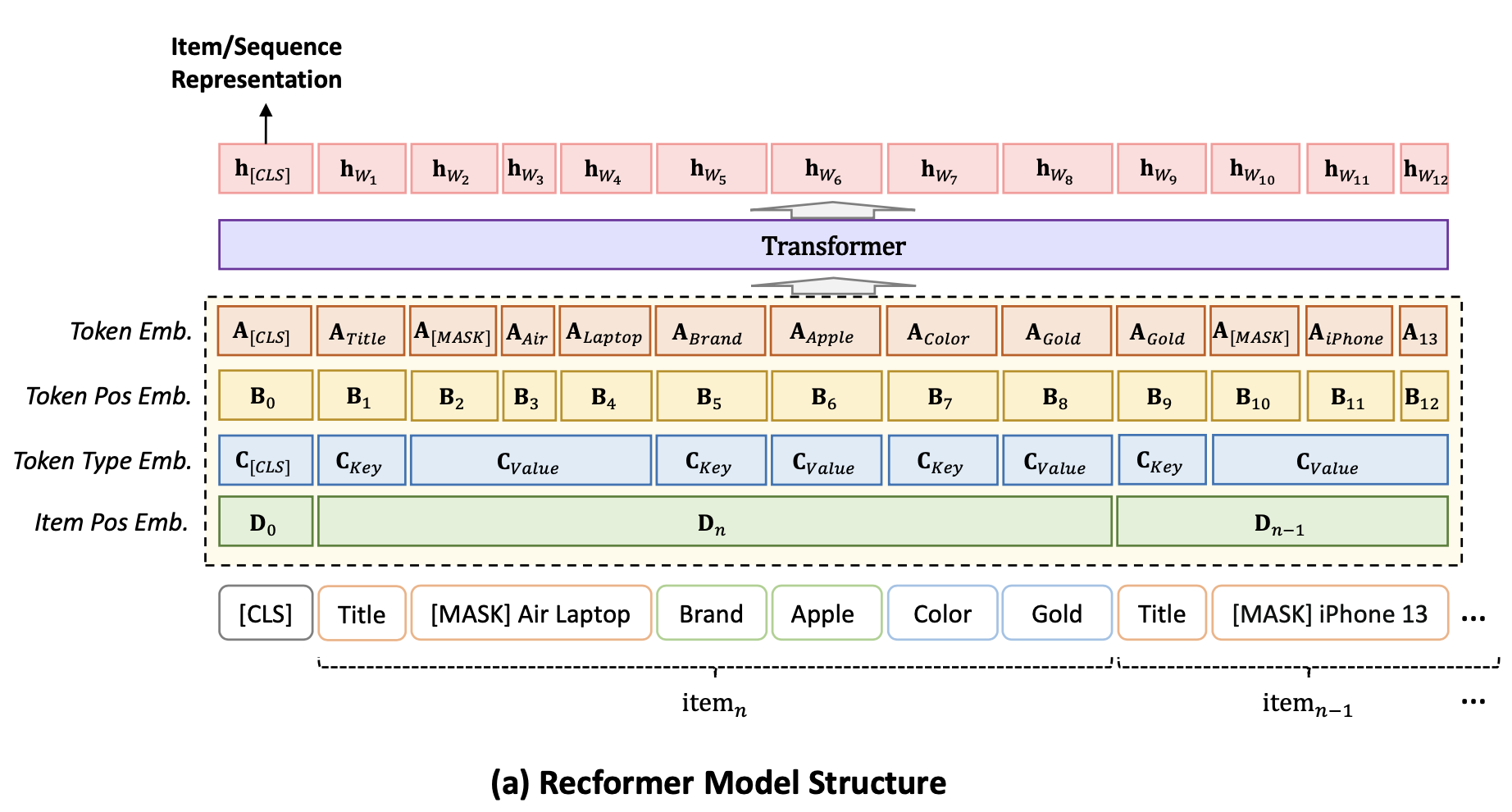
임베딩
Recformer의 임베딩은 4가지 임베딩의 합으로 이루어집니다. 이때 토큰 임베딩과 토큰 위치 임베딩은 일반적인 언어 모델에서의 임베딩과 동일합니다. 여기서 변경된 부분은 토큰 유형 임베딩, 새롭게 추가된 부분은 아이템 위치 임베딩입니다.
- 토큰 임베딩 (Token Embedding)
- 토큰 위치 임베딩 (Token Position Embedding)
- 토큰 유형 임베딩 (Token Type Embedding)
- 아이템 위치 임베딩 (Item Position Embedding)
3. Token Type Embedding
토큰 유형 임베딩은 token_type_ids의 임베딩입니다. 기존의 언어 모델은 token_type_ids 가 각 토큰이 어떤 문장에 속하는지를 나타내는 리스트였다면 Recformer에서는 각 토큰이 아이템의 속성 이름인지 아니면 값인지를 나타내는 리스트를 의미합니다.
위의 그림에서 [CLS] 토큰은 0으로, Title, Brand, Color는 속성명이기 때문에 값이 1로, 각 속성에 해당하는 정보들은 속성값이기 때문에 2로 할당됩니다. input이 배치 단위일 경우에는 배치 내의 최대 토큰의 길이만큼 패딩이 생성되고, 패딩 값은 3으로 할당됩니다.
4. Item Position Embedding
아이템 위치 임베딩은 item_postion_ids 의 임베딩입니다. 유저의 아이템 시퀀스는 여러 개의 아이템으로 이루어져있기 때문에 각 토큰이 몇 번째 아이템의 정보인지를 나타냅니다.
마찬가지로 [CLS] 토큰은 0으로 할당되며 input이 배치 단위일 경우에는 배치 내의 최대 토큰의 길이만큼 패딩이 생성되고, 패딩 값은 config.max_item_embeddings - 1로 할당됩니다.
예시)
# 아이템 시퀀스
items1 = [{'pt': 'PUZZLES',
'material': 'Cardboard++Cartón',
'item_dimensions': '27 x 20 x 0.1 inches',
'number_of_pieces': '1000',
'brand': 'Galison++',
'number_of_items': '1',
'model_number': '9780735366763',
'size': '1000++',
'theme': 'Christmas++',
'color': 'Dresden'},
{'pt': 'DECORATIVE_SIGNAGE',
'item_shape': 'Square++Cuadrado',
'brand': 'Generic++',
'color': 'Square-5++Cuadrado-5',
'mounting_type': 'Wall Mount++',
'material': 'Wood++Madera'}]
# 토큰화 결과 (아이템은 최신순(역순)으로 정렬됨)
['<s>', 'pt', 'DEC', 'OR', 'ATIVE', '_', 'S', 'IG', 'NA', 'item', '_', 'shape', 'Square', '++', 'Cu', 'adr', 'ado', 'brand', 'Generic', '++', 'color', 'Square', '-', '5', '++', 'Cu', 'adr', 'ado', 'mount', 'ing', '_', 'type', 'Wall', 'ĠMount', '++', 'material', 'Wood', '++', 'M', 'ader', 'a', 'pt', 'PU', 'ZZ', 'LES', 'material', 'Card', 'board', '++', 'Cart', 'ón', 'item', '_', 'dim', 'ensions', '27', 'Ġx', 'Ġ20', 'Ġx', 'number', '_', 'of', '_', 'pieces', '1000', 'brand', 'Gal', 'ison', '++', 'number', '_', 'of', '_', 'items', '1', 'model', '_', 'number', '97', '807', '35', '36', '67', 'size', '1000', '++', 'theme', 'Christmas', '++', 'color', 'D', 'res', 'den', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
# token_type_ids
[0, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 1, 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 1, 2, 2, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 1, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3]
# item_position_ids
[0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31]
학습 프레임 워크
순차적 추천을 위한 언어 모델을 갖추기 위해 논문에서는 사전 학습 후 2단계 미세 조정 방식을 제안합니다.
사전 학습
사전학습의 목표는 다운스트림 작업을 위한 고품질의 파라미터 초기화를 얻는 것입니다. 추천만 고려하는 기존의 순차적 추천 사전 학습 방법과는 달리, 언어 이해와 추천을 모두 고려해야 합니다. 따라서 Recformer는 사전 학습을 위해 아래 두 가지 작업을 채택했습니다.
- MLM: 마스크 언어 모델링
- IIC: 아이템-아이템 Contrastive Learning
MLM Task
MLM은 일반적인 언어모델 학습 방식과 똑같이 토큰의 15%를 무작위로 선택하고 해당 15% 중의 80%를 [MASK], 10%를 무작위 토큰으로 교체, 10%는 그대로 유지합니다.

Loss
loss function은 cross entropy loss입니다.

IIC Task (아이템-아이템 Contrastive )
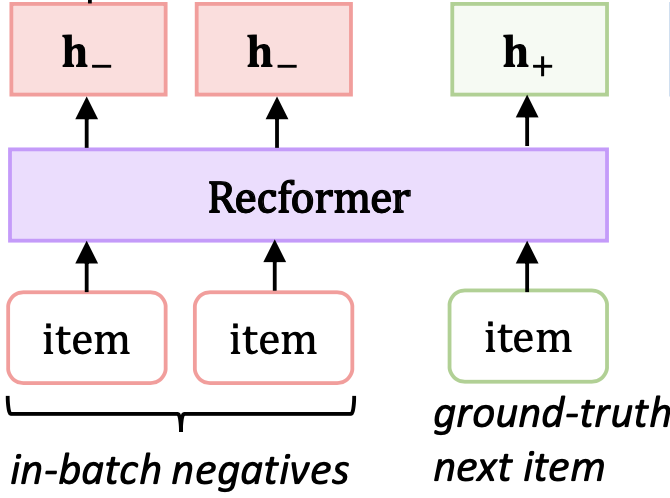
논문에서 제안하는 contrastive 작업의 아이디어는 동일한 유저 시퀀스 내의 아이템들은 서로 가깝게, 서로 다른 유저로부터 나온 아이템은 멀게 학습되도록 하는 것입니다.
이를 위해서 학습 데이터 생성 시 아이템 시퀀스를 두 개의 리스트로 분리합니다. 시퀀스 내의 i 번째 아이템을 정답 아이템으로 설정하고, 해당 아이템의 이전의 등장한 아이템으로 나눕니다.
만약 batch_size=3 일 경우 즉, 유저 3명에 대한 아이템 시퀀스가 하나의 배치로 주어지면 각 유저마다 ground-truth next item 을 시퀀스의 중간부터 마지막 까지 중에서 랜덤으로 정하고 뒷부분을 버린다음 두개의 리스트에 나눠 담습니다.

그 다음 위에서 설명한 임베딩을 거쳐 Recformer에 주입한 후, 각 유저 아이템 시퀀스의 특징 벡터를 얻습니다.

그 다음 코사인 유사도 행렬을 구합니다. 목표는 해당 코사인 유사도 행렬과 유저 시퀀스의 인덱스 [0, 1, 2] 와의 cross-entropy loss를 구하고 이를 낮추도록 학습하는 것입니다. 배치 내의 다른 유저의 아이템 시퀀스를 negative로, 같은 유저로부터 나온 아이템을 positive로 하여 contrastive learning을 수행한 것이므로 논문에서는 이를in-batch negatives 라고 표현하였습니다.
같은 배치의 다른 유저의 아이템을 negative로 설정하면, 유저간 아이템이 겹치는 경우 False Negative의 오탐을 발생할 수 있습니다. 그러나 논문에서는 데이터 셋의 크기가 커질수록 즉, 아이템 수가 매우 많아질 경우에는 오탐이 발생할 가능성이 적다고 말하고 있습니다. 추천 성능에 큰 해를 끼치지 않으면서도 supervised learning을 하는 것보다 훨씬 높은 훈련 효율성을 제공한다고 주장합니다.

Loss
최종적으로 사전학습시의 loss는 MLM loss와 IIC loss 의 합으로 이루어집니다
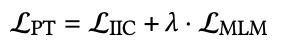
2 단계 fine-tuning
만약 사용자의 데이터셋이 작을 경우 위의 사전학습 모델의 false-negative 문제로 인한 성능 저하가 발생할 수 있습니다. 이를 해결하기 위해 논문에서는 2-stage fine tuning 알고리즘을 제안하였습니다.
기본 아이디어는 모델이 이미 사전학습되었지만, 사전 학습된 모델의 아이템 표현은 다운스트림 데이터 셋에 대한 추가학습을 통해 개선할 수 있다는 것입니다.
모든 배치에서 모든 아이템을 인코딩하는 것은 비용이 많이 들기 때문에 에포크마다 전체 아이템을 인코딩해서 Item feature matrix I를 얻고(4행), 이를 Item-Item Contrastive Learning 태스크의 정답으로 사용합니다(5행). 평가 결과가 개선될 때마다 그때의 아이템 표현 I 를 다음 학습의 입력으로 사용합니다. 이렇게 1단계에서는 에포크마다 전체 아이템의 최선의 특징 벡터 I가 얻어지고, 해당 벡터로 시퀀스 내의 next-item을 맞추도록 모델을 학습하여 모델 파라미터 M이 업데이트됩니다.
2단계에서는 1단계 결과로 나온 최선의 아이템 표현 I를 동결하고, 이를 학습에 활용해서 검증 데이터셋에서 최상의 성능을 얻을 때까지 모델 파라미터만 계속 업데이트되도록 모델을 계속 훈련합니다.

사전학습과 파인튜닝에서의 다른점은 유사도 계산시 in-batch negative와의 유사도만 계산하는 것이 아니라 전체 아이템과의 유사도를 비교하도록 fully softmax를 사용하는 것입니다


성능 평가
성능평가를 위해 다양한 범주의 Amazon 리뷰 데이터셋에 대해 사전학습 및 미세조정을 수행하였으며, 사전학습과 미세조정에 사용된 데이터의 카테고리는 서로 배제적으로 설정되었습니다.
비교대상은 이전에 제안되었던 아이템 ID 만 사용하는 모델들 , 아이템 ID와 Text를 모두 활용하는 모델들, Recformer와 같이 Text만 사용하는 모델들입니다.
추천의 성능을 평가하기 위해서 널리 사용되는 세 가지 메트릭을 평가 메트릭으로 채택하였습니다.
N은 유저에게 제안되는 아이템의 수이며, 논문에서는 10개로 설정하였습니다.
- NDCG@N: 추천시 순위에 가중치를 두고 가장 이상적인 랭킹(정답 랭킹)일 수록 점수가 높아지는 방식
- Recall@N: 사용자가 실제로 관심있는 아이템 중에 모델이 추천한 아이템의 비율
- MRR (Mean Reciprocal Rank): 사용자가 선호하는 아이템이 리스트 중 어디에 위치해 있는지에 중점을 둔 평가 기법
결론적으로 Recformer는 Instrument 카테고리의 Recall@10을 제외한 모든 데이터셋에서 전반적으로 가장 우수한 성능을 달성하였습니다.
아래 표에서 밑줄은 두 번째 우수한 성능, 볼드표시는 가장 우수한 성능을 나타냅니다. Improv.는 이전의 최고 성능대비 Recformer의 상대적 개선도를 나타냅니다.

'Review' 카테고리의 다른 글
| [리뷰] Udemy - Langchain으로 LLM 기반 어플리케이션 개발하기 (0) | 2024.04.14 |
|---|---|
| [공유] NAVER Cloud SUMMIT (2022.12.14 / 온라인) (0) | 2022.11.17 |
| [리뷰] 빅데이터 시대, 성과를 이끌어 내는 데이터 문해력 (0) | 2022.07.23 |


